平均がつくる「理想」と、分布が示す「現実」
「平均年収が上昇しました」といった経済ニュースを時々耳にしますが、この手のニュースを聞いて「確かに生活が良くなった」と実感する人は、意外と多くないのではないでしょうか?。むしろ多くの人は「自分の給料は上がっていない」と感じています。この違和感はどこから生まれるのでしょうか。
実は、その原因の一つは平均という指標そのものにあります。
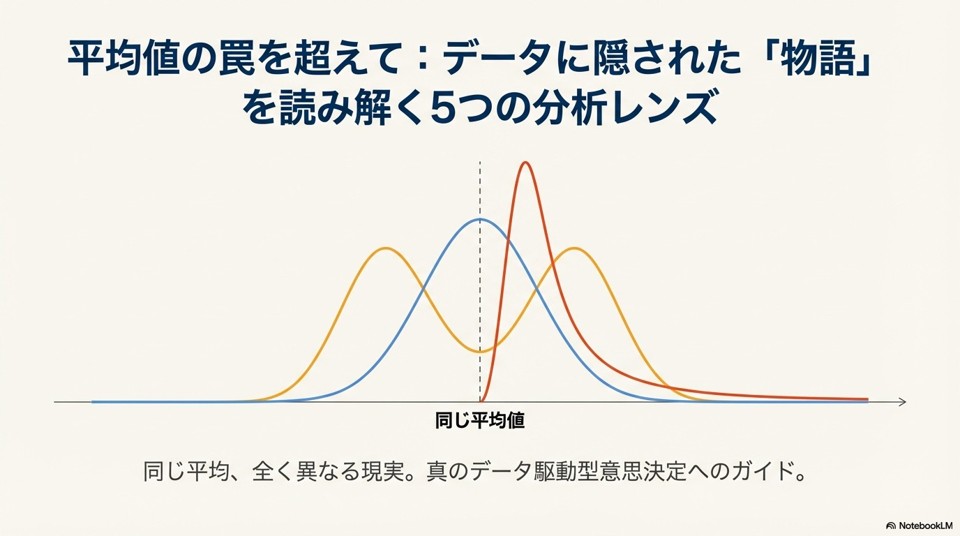
平均は、全体を一つの数字で表す便利な指標です。しかし同時に、分布の構造を消してしまうという特徴も持っています。たとえば、社会の所得分布が次のようになっていたとします。
・一部の超富裕層の年収だけが急激に上がる(パワーロー)
・中間層が減り、低所得層と高所得層に分かれる(二極化)
このような状況でも、平均値は上昇します。するとデータ上は「社会全体の年収が上がった」ように見えます。
しかし実際には、多くの人の所得は変わっていないか、むしろ下がっている可能性すらあります。
つまり平均が示しているのは、必ずしも現実の生活実感ではなく、ばらつきを均した後の“理想化された社会”なのです。
古典的な統計手法は、平均や回帰直線のように、データを滑らかな形で説明することを得意としています。しかし現実の社会や市場は、必ずしもそのような形ではありません。
・パワーロー分布
・ロングテール
・多峰性(複数の山を持つ分布)
・外れ値の集中
このようないびつな構造こそが、むしろ現実の姿であることも多いのです。
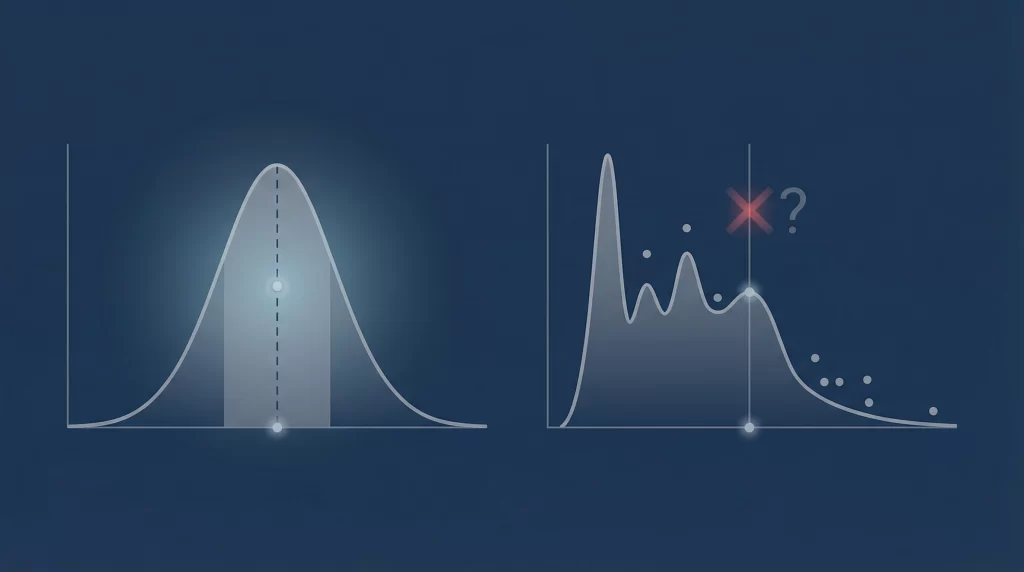
もし平均だけを見てしまうと、こうした構造はすべて見えなくなります。その結果、データは「みんなが少しずつ良くなっている」という理想的な物語を作り出します。
しかし分布を見れば、まったく異なる現実が現れます。そこには、格差や集中、断絶といった現実の構造が存在しています。
もしかすると、私たちが感じている「理想と現実のギャップ」は、社会の問題そのものというより、平均という“見せ方”が生み出している錯覚なのかもしれません。
理想を聞かされて現実に失望する。これからのデータ分析に求められるのは、平均ではなく、分布構造そのものを見る視点なのではないでしょうか。