
平均値は、便利です。けれど「便利さ」が、現実を見えなくする瞬間があります。
*ミュートしています
従来の統計学は、正規分布と平均値を中心に世界を整理してきました。確かに、ばらつきが小さく、反応が素直に揃う領域では強力です。しかし現代のデータ、とくに医療・行動・購買・教育・組織など“人”が絡む領域では、分布はしばしば歪み、裾が伸び、複数の山を持ち、そして時間とともに形を変えます。ここに「平均値の罠」が生まれます。
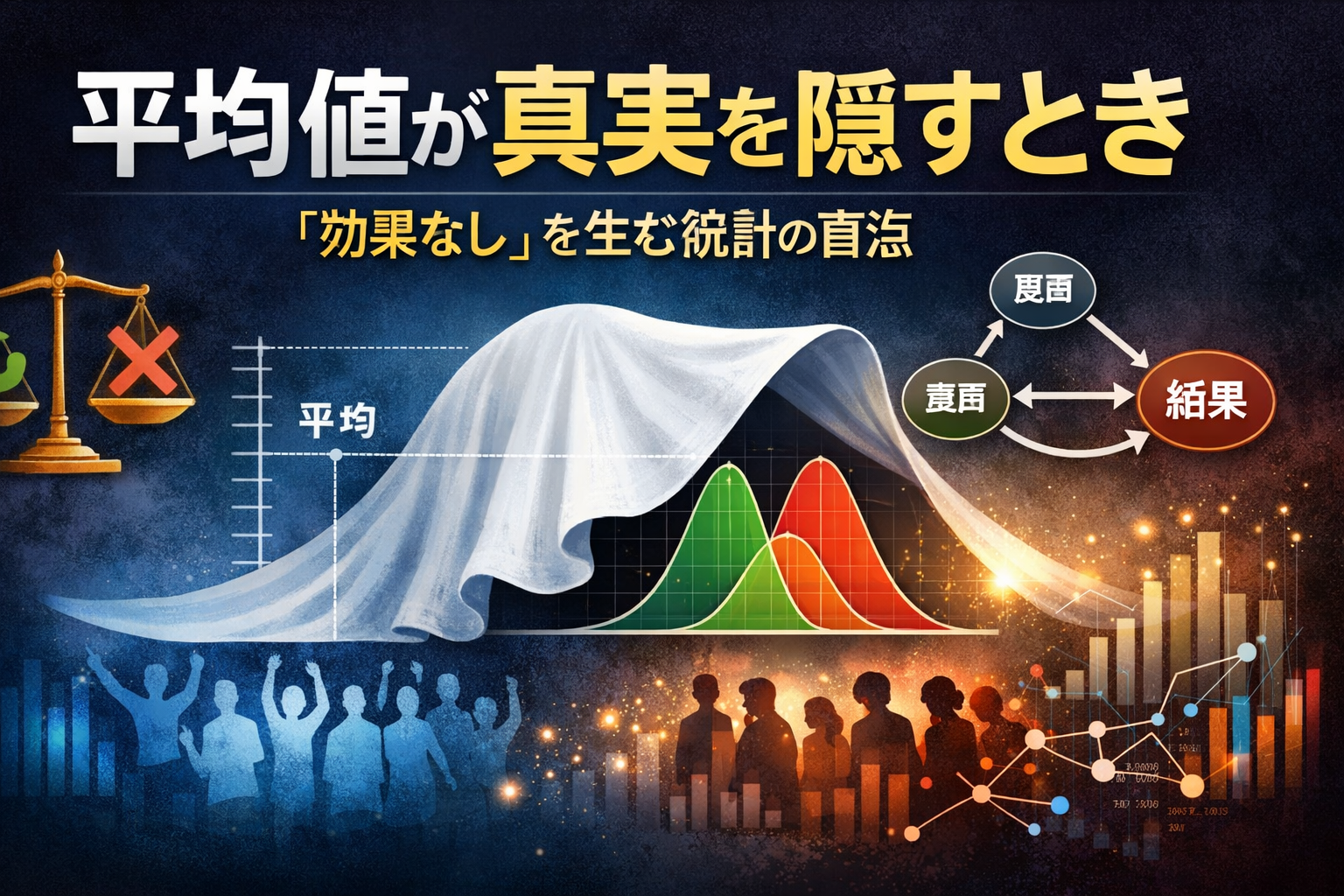
たとえば、同じ施策を打ったのに「ある層は大きく改善し、別の層は悪化した」。こうした相反する反応が集団内で同時に起きると、平均値だけを追う評価では、プラスとマイナスが相殺されて“効果なし”に見えてしまいます。現場の感覚としては「効いた人は確かにいる」のに、分析上は「有意差なし」。このズレが意思決定を鈍らせ、結果として“誰にも刺さらない画一的施策”を延命させてしまうのです。
そこで必要になるのが、平均ではなく「分布そのもの」を読む視点です。分布構造分析(DSA)は、効果の有無を一本の数字で裁くのではなく、反応がどこで・どの方向に・どの程度“再配置”されたのかを可視化します。二極化が進んだのか、特定の山だけが動いたのか、裾野の伸びが起きたのか――つまり「何が起きたか」を誤魔化さずに捉える。これにより、相殺による“効果なし”誤認を避け、「効く人がどこにいるか」を見つけ出せます。
ただし、分布が変わったことが分かっても、次の問いが残ります。「なぜ、その人たちにだけ効いたのか?」。ここで登場するのが因果グラフ(DAG)です。DAGは、要因同士の関係を“因果の仮説構造”として組み立て、交絡や媒介、選択バイアスといった見落としやすい落とし穴を整理します。DSAが現象の輪郭を描くなら、DAGはその背後にある“理由の筋道”を明らかにする道具です。現象の把握(DSA)から原因の特定(DAG)までを一気通貫で扱えることが、このアプローチの強みになります。
平均で一つにまとめる時代から、分布と因果で“違い”を前提に最適化する時代へ。画一的な施策を繰り返すほど、成果が頭打ちになるのは当然です。多様なデータ、多様な人、多様な反応が当たり前になった今こそ、統計学の使い方そのものにパラダイムシフトが求められています。