
マーケティングや営業の現場で「ロジスティック回帰」という言葉を聞いたことはあっても、実際には「統計担当にお任せ」というケースが多いのではないでしょうか。ところが今、そうした“平均で意思決定する世界”そのものが限界を迎えつつあります。
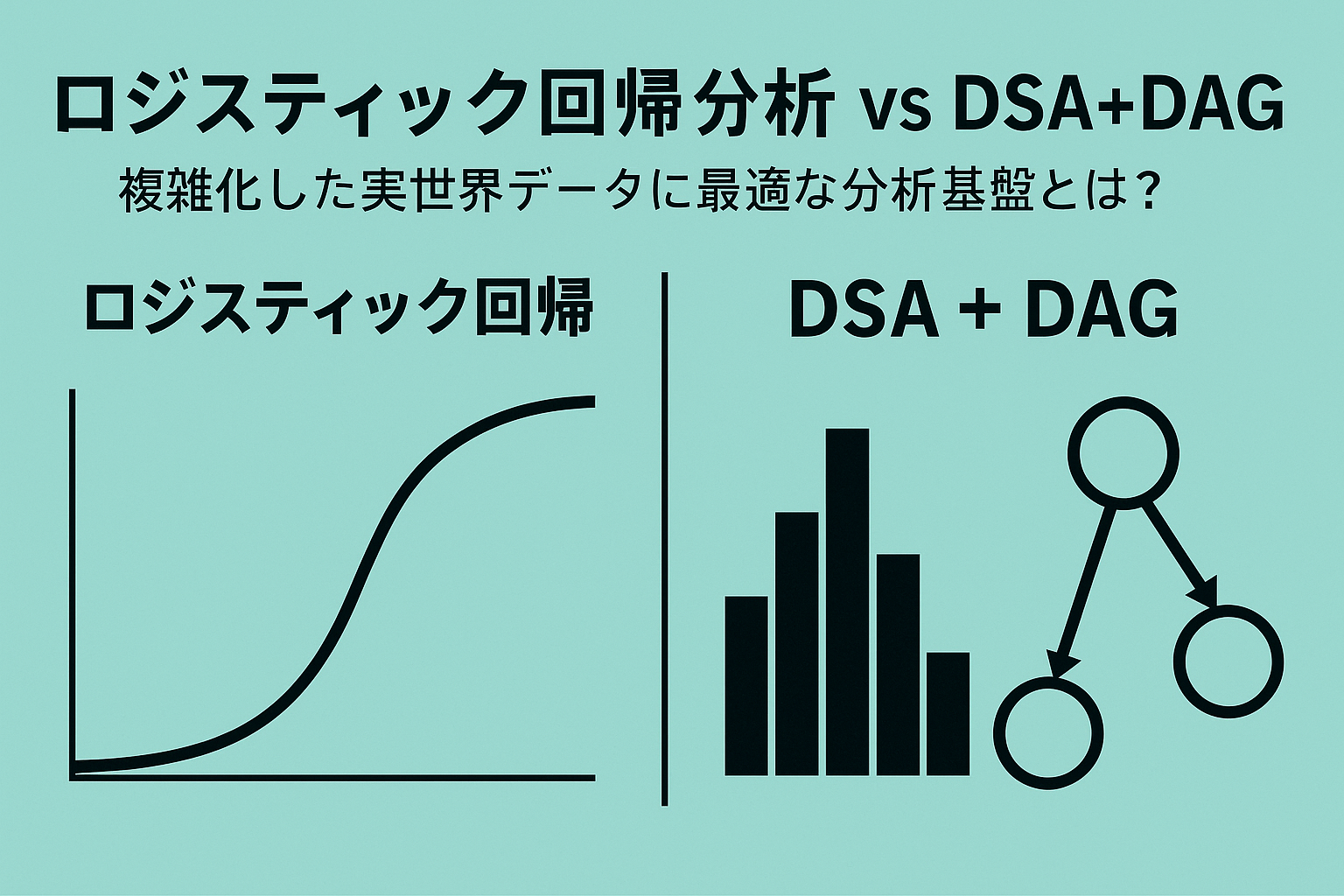
ロジスティック回帰は、ある施策を行ったかどうかで「買う/買わない」「離脱する/継続する」といった結果の確率を推定するには、とても分かりやすい手法です。ただし前提は、「お客様はだいたい一つのまとまり(単峰)として振る舞う」という世界観です。平均的な顧客像を描き、その顧客にどの要因が効いているかを見る──これが従来の発想でした。
しかし現実のビジネスはどうでしょうか。価格に極端に敏感な層、ブランドへのロイヤルティが異常に高い層、情報に過剰反応する層…。データをよく見ると、多峰性や極端なクラスターが存在し、「平均的なお客様」などほとんどいません。ここで登場するのがDSA + DAGです。
DSA(分布構造分析)は、まず「どんなタイプの顧客集団が、どのような構造で存在しているか」をあぶり出します。ロジスティック回帰が1本の滑らかな曲線で世界を表現しようとするのに対し、DSAは「山がいくつあるのか」「どこの山がビジネス的においしいのか」をそのまま見せてくれます。結果として、本当に狙うべきクラスターはどこか、そこにどれだけ資源を投下すべきかが、数字と図で明確になります。
さらにDAG(因果グラフ)は、「相関」と「因果」を切り分ける武器になります。売上とキャンペーン接触が相関していても、「売上が高い顧客ほどキャンペーン対象に選ばれていた」という逆因果の可能性は常にあります。DAGは、どの変数を調整すれば因果効果を取り出せるかを構造として示してくれるため、「本当に効いた施策は何か」を見誤りにくくなります。これは、限られた予算をどこに振り向けるかを判断する経営にとって、極めて実務的な価値です。
もちろんDSA + DAGにも弱点はあります。新しい概念であるがゆえに、社内での理解・教育コストが必要ですし、「オッズ比1.5倍」といった教科書的な指標に比べると、成果の説明がやや構造的・ビジュアル寄りになります。しかし、顧客が多様化し、市場がゼロサム化していく中で、「平均的な顧客に平均的な施策を打つ」だけでは勝てないことは、ほとんどの現場が肌で感じているはずです。
ロジスティック回帰は、依然として“標準語”としての役割を果たします。一方で、これからの競争環境では、分布構造(どんな顧客がどの比率で存在するか)と因果構造(何が結果を動かしているのか)を同時に押さえた上で、戦略と資源配分を設計できるかどうかが、企業間の決定的な差になります。
「平均で見るか、構造で見るか」。
これは単なる分析手法の選択ではなく、ビジネスそのものの“意思決定のOS”をバージョンアップするかどうか、という問いかけなのかもしれません。
*ミュート解除してください。