

犯罪は全体的に満遍なく起きるのではなく、盲点を突いてきます。つまり外れ値や特異点です。相関の強さや確率の高さを中心とした従来型の統計手法が苦手な領域です。統計学は平均的な傾向を把握することに長けていますが、発生頻度が低く特殊な条件が重なった際に起きる犯罪の予測には得意ではありません。防犯において重要なのは、全体像に埋もれてしまう分布の偏りや特異点を特定し、その背後にある複雑な因果関係を解明することにあります。そこで、データの歪みや局所的な集積を捉えるDSAと、事象の構造を可視化するDAGを組み合わせる手法が有効となります。このアプローチにより、表面的な相関関係ではなく「なぜその場所で異常が起きるのか」という発生構造を深く理解することが可能になります。統計的な「典型」を追うのではなく、非典型的なリスクを科学的に捉える視点こそが、現代の防犯戦略には不可欠と言えるでしょう。
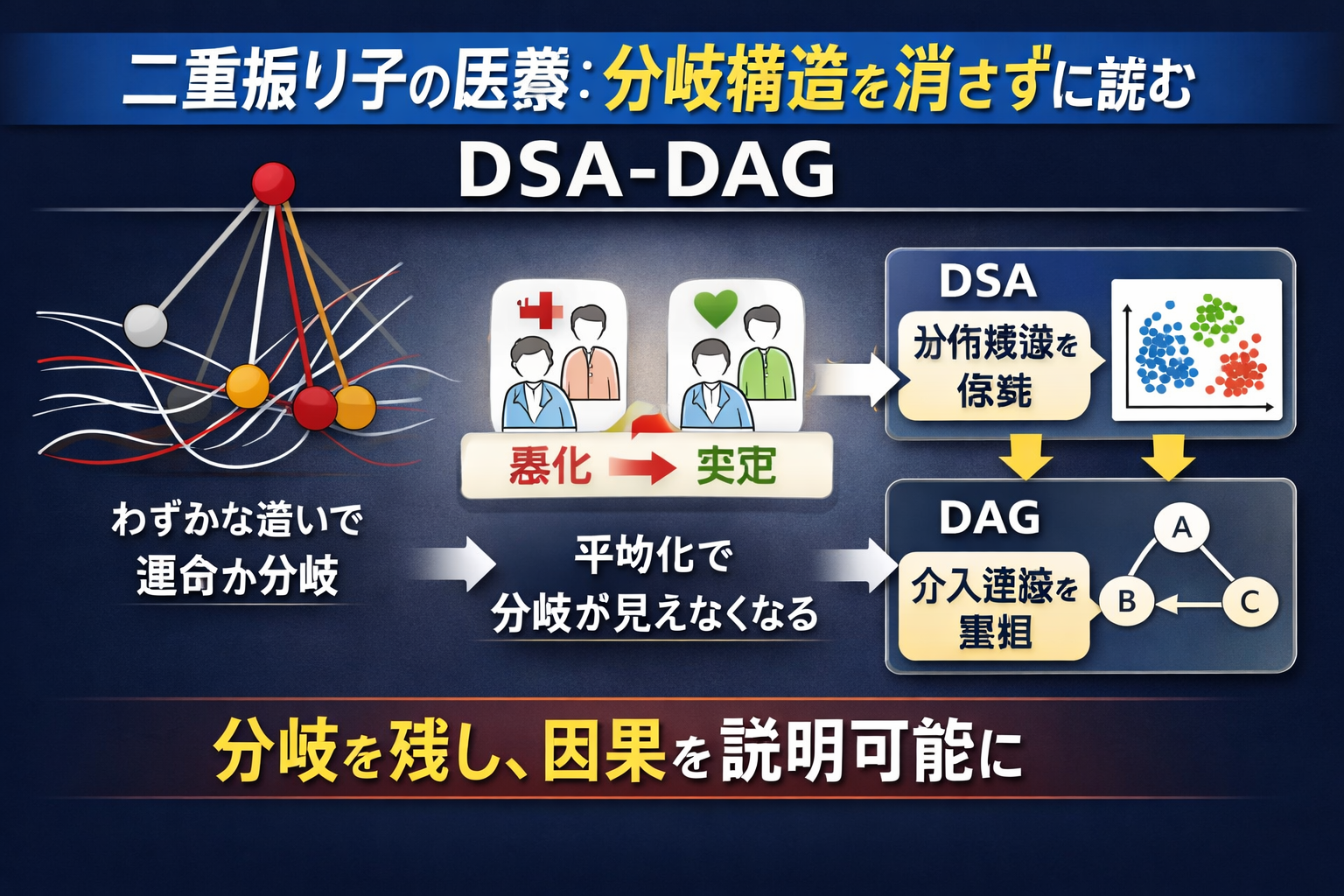
医療データは、初期条件に敏感に依存する傾向がしばしば見られます。これは、初期状態のわずかな違いが質的に異なる軌跡へと伝播していく二重振り子によく表れる現象です。臨床集団においても、患者の背景、併存疾患の負担、あるいは測定されていない生活習慣因子のわずかな違いが、結果に不釣り合いに大きな違いをもたらす場合、同様の分岐が生じます。因果分析の前にこれらの分布構造を平均化または平滑化する分析フレームワークは、治療反応の差異を生み出す分岐構造をまさに消し去ってしまう危険性があります。DSA-DAGは、この分岐構造を崩壊させるのではなく維持し、得られた構造マップを、品質ラベル付きの因果仮説生成を通じて説明可能な介入設計に結びつけるように設計されています。

DSA(分布構造分析)とDAG(有向非巡回グラフ)を組み合わせることで、因果推論における客観性を高める手法について解説しています。従来のDAGは専門家の主観に依存しやすいという弱点がありましたが、本手法はDSAによってデータの歪みや層を事前に把握し、仮説の精度を向上させることを目指します。最も重要な点は、単なる静的なデータ分析にとどまらず、介入後に生じる構造変化を観測することで因果仮説の妥当性を検証するという動的なアプローチにあります。これにより、主観的な仮説を反証可能で監査可能な科学的プロセスへと引き上げることが可能になります。既存の構造探索AIとは異なり、因果を変化のプロセスとして捉える点に、この手法独自の新規性と優位性が存在します。

AIや機械学習への期待が高まる一方で、「とにかくデータを入れれば何か分かる」という発想も広がっています。しかし、それは危うい考え方です。なぜなら、問いそのものが間違っていれば、どれほど高度なAIを使っても、もっともらしい誤答を大量生産するだけだからです。 現代のAI活用においては、単に高度な機械学習やベイズ推論を回すだけでは不十分であり、その前提となる問いの設計が不可欠です。データの分布構造を捉えるDSAと変数間の因果関係を可視化するDAGを、分析の土台として導入することが重要です。集団の多様性や論理構造を正しく整理しなければ、どれほど精緻なAIモデルであっても無意味な結論を導き出しかねません。つまり、AIを単なる効率化の道具ではなく競争優位の源泉とするためには、数理モデルを動かす前の構造設計こそが大切になります。したがって、技術的な精度を競う以上に、AIが正しく機能するための「正しい問い」を設計できる人材がこれからの時代には求められています。

人類は今、歴史上はじめて「自分たちよりも高い頭脳を持つ存在」と向き合っています。それがAIです。
火や農耕、産業革命、インターネット。これまでの技術革新は、人類の能力を拡張するものでした。しかしAIは違います。AIは能力を拡張する対象ではなく、能力そのものの優劣を逆転させる存在です。
計算速度、記憶容量、探索能力、最適化。多くの知的作業において、すでに人間はAIに及びません。この事実をどう受け止めるかで、社会は急速に二極化していきます。
二極化①
「変わらなくていい」と信じ続ける人たち
一方には、
- AIはあくまで道具
- 人間の本質は変わらない
- 今の延長線で何とかなる
と考える人たちがいます。
彼らは決して怠惰ではありません。
むしろ真面目で、これまでの成功体験や専門性を大切にしてきた人ほど、この側に立ちやすい。
しかしAI時代において危険なのは、能力不足ではなく前提の固定です。
「そのうちAIを使えばいい」
「必要になったら学べばいい」
こうした姿勢は、AIが“選択肢”だった時代には通用しました。
しかし今やAIは、評価基準・意思決定速度・説明責任の形式そのものを先に書き換えています。
気づいたときには、
AIを使うかどうかを選ぶ立場ではなく、AI前提の世界に適応させられる立場になっている。
これが第一の極です。
二極化②
「人間の役割を再定義しようとする人たち」
もう一方には、
- AIは人類を超えた知性である
- だからこそ、人の役割を再定義しなければならない
と考える人たちがいます。
彼らはAIと競おうとはしません。
計算でも記憶でも勝てないことを、冷静に受け入れている。
その代わりに問うのは、
- 何を価値とするか
- どの問いを立てるか
- 結果に誰が責任を持つのか
知性の使い道の設計です。
AIは答えを出せます。
しかし「どの問いに答えるべきか」は決められません。
最適解は示せても、「その最適化が正しいかどうか」は引き受けられない。
ここに、人間が残される役割があります。
この二極化は、努力では埋まらない
重要なのは、この分断が
- 学歴
- 年齢
- ITスキル
で決まるものではないという点です。
分かれ目はただ一つ。
AIを前提に世界を見るか、AIを例外として扱おうとするか。
この差は、努力量では埋まりません。
前提が違うからです。
そしてこの二極化は、今後さらに拡大します。
中間は消えていく。
「なんとなく様子を見る」という選択肢は、急速に居場所を失います。
人類は今、試されている
人類史上初めて、自分たちよりも賢い存在と共存する時代に入りました。
ここで問われているのは、知能でも、生産性でも、スピードでもありません。
覚悟と設計力です。
AIに使われる側になるのか。AIを前提に社会と意思決定を設計する側に立つのか。
これは技術論ではなく、
生き方の選択です。
そしてこの選択は、静かに、しかし不可逆に、すでに始まっています。

これまで、とりあえずなんでもかんでもデータを取っておけば、あとで分析すれば「なにか予期せぬ面白い発見があるかも」と思っても、現実には、あとから解析してみても「期待は不発」で終わる。これ、けっこうよく聞く話です。
この「期待は不発」でおわる問題は、データ不足というより、後から解析する側が置いている前提に起因しています。典型的には次の3つです。
1) 解析は「平均の世界」に引っ張られる
多くの解析は、まず平均(差)や線形関係を見にいきます。
平均は全体を一言で言える反面、現実に多い「混ざりもの」を消します。
- 効く人と効かない人が混在している(二峰性)
- 少数の強い反応者が全体を支配している(ロングテール)
- ある条件を境に挙動が変わる(閾値)
こういう構造は、平均を取った瞬間に無効化します。つまり、面白いはずの“差”が、解析の入口で既に平坦化される。これが「何も出ない」の第一原因です。
2) 「問い」がないまま解析すると、出てくるのは“説明しやすいもの”だけ
とりあえず集めたデータは、裏を返すと「何を見るか」が固定されていません。
この状態で後から解析すると、人はどうしても
- 手元にある変数で説明できる
- 絵にしやすい
- 既存の枠に当てはめやすい
方向へ寄ります。結果として、出てくるのは「想定内」「教科書的」「既視感のある結論」になりがちです。
発見がないのではなく、発見の入口が“都合の良い説明”に偏るということです。
3) 現実データは「原因と結果」が最初から混ざっている(交絡・選択・介入の歪み)
特にRWDでは、データは自然発生的に集まるので、純粋な比較になりません。
- そもそも治療や介入が“選ばれている”(重症度や医師判断など)
- 測定の頻度自体が状態に依存する
- 欠測がランダムではない
- フォローアップが均一ではない
この状態で単純に相関を見ると、「関係がある/ない」が揺れます。
そして解析者は、揺れを収束させるために
- 調整変数を足す
- 欠測を補完する
- 分布を整える
方向へ進みますが、ここで“本来の構造”がさらに見えにくくなることがあります。
つまり、RWDの世界では、解析の難しさがデータの中に埋め込まれている。これが「後からやっても成果が出ない」第二原因です。
とりあえず集めたデータが、あとから“問いを生む”状態を作る
そして、その問いが“検証できる形”で残るようにする
ということです。
「集めたのに何も出ない」という経験の無力感は、
時間やコストが無駄になること以上に、次に何をすればいいかが残らないことです。
「DSA+DAG」は、この“次が残らない”を変えにいきます。
たとえば、プロダクトで新機能を追加したとします。
「継続率が上がるはず」「CVが上がるはず」と期待して、ログも一通り取った。
ところが1か月後に分析すると、結果はこうです。
- 全体のCV:ほぼ変わらない
- 継続率:微増だけど誤差っぽい
- 平均滞在時間:むしろ少し下がった
で、会議の結論がだいたいこれになります。
「効果は限定的でした」「次の施策を考えましょう」
ここで“あるある”なのは、平均で見る限り、何も起きていないように見えることです。
でも現場の感覚としては、「刺さった人は明らかに喜んでいる」という手応えがある。なのに数字に出ない。
このとき起きているのは、だいたい次のどれかです。
- 効いた層と効かなかった層が混ざって平均で相殺されている
- 少数のヘビーユーザーだけが強く反応して、全体平均には出ない(ロングテール)
- そもそも機能を“使った人”が偏っている(選択バイアス)
- 「使った→良くなった」ではなく「元から熱量が高い人が使った」だけ(逆因果っぽい)
つまり、“何も出ない”のではなく、
何かが起きているのに、平均のレンズだとそれが見えない。
同様に、RWDからRWE構築のメッセージを雑に要約すると、
- RWDをとにかく集めろ(蓄積を進めろ)
- RWEにしろ(意思決定に使える形にしろ)
- しかも因果で説明できるようにしろ
- その方法は各自で考えろ(考えろと言う)
となっていて、「とりあえずデータだけ取っておけば、あとで分析して面白い発見があるかも」と趣がほぼ同型です。
違いがあるとすれば、国の要求はさらに一段きつくて、
「何か見つけろ」ではなく 「因果で説明しろ」まで要求している点です。
つまり、単なる“発見”ではなく、意思決定に耐える説明責任を求めていることです。
だから現場では、
- データは溜まる
- でも「切り取り前提」の解析では因果が立ちにくい
- 結果、「RWDはあるがRWEにならない」が起きる
という“あるあるループ”が、構造的に再生産されやすくなるのです。
では、どうするか?
RWDを集めるだけではRWEにならない。
RWEにするには、RWDを切り取る前に“あるがまま”の構造を捉え、因果として説明できる形に落とす道具立てが必要。
その解決策として、DSA+DAGを置くと、単なる解析手法ではなく、要求に応えることが出来る「現実的な解法」となります。
- DSAは、まず「全体平均」ではなく、分布が割れていないかを見る
(一部が大きく改善して、別の一部が悪化していないか、少数の尖りがないか) - そしてDAGで、「誰がその機能を使う(選ぶ)のか」という偏りを含めて、
“効いた”のか“選ばれただけ”なのかを切り分ける問いにする
これができると、結論が「効果なし」で終わりません。
「効く人の条件はこれ」「効かない人はここが詰まっている」
「次の打ち手はプロダクト改善か、導線か、対象の切り替えか」
と、“次の一手が残る”形になります。
これまでのRWD活用は、どこかで「必要なデータだけ切り取って、仮説を検証する」前提になりがちでした。もちろん合理的です。ただ、そのやり方だと、RWDの一番大事な特徴、“現実の混ざり方、偏り方、ばらつき方”というリアルが、解析の入口でそぎ落とされてしまいます。結果として、あとから解析しても「平均的にはこうです」という話に寄り、現場が本当に知りたい「誰に、なぜ、どう効くのか」が残らない。これが“RWDがRWEになりきらない”典型パターンです。
DSA+DAGが狙うのは、その逆です。RWDを「切り取る」より先に、まずあるがままの分布構造として見る。割れ(効く群/効かない群)、ロングテール(少数が全体を動かす)、閾値(境目で挙動が変わる)、欠測や選択の偏りなど、こうした現実のクセを、ノイズとして消さずに情報として保持します。すると、RWDの中に埋まっていた「分岐」や「偏り」が表に出てきて、データの側から「問い」が立ち上がるようになります。
ただし、分布のクセが見えただけではRWEにはなりません。そこでDAGです。DAGは、その分岐や偏りを「因果の問い」に翻訳します。治療が選ばれた理由(選択バイアス)、重症度や背景因子の混入(交絡)、測定頻度や欠測が結果に与える影響など、それらを構造として整理し、「どこを調整し、何を介入とみなし、何をアウトカムと定義すべきか」を明確にします。ここまで落とすことで、RWDは“ただの相関の集まり”から、検証可能で意思決定に使える因果の証拠へと変わります。

高市内閣が高い支持率を背景に解散総選挙に踏み切りました。この判断は吉と出るのか、凶と出るのでしょうか。政治の世界では暗黙知や経験則が語られがちですが、ここではあえて「因果モデルで占う」という前提に立ちます。支持率がとか野党がとか2値で語られることが多いですが、分析の鍵は、支持率という“平均値”をそのまま信じないことです。
小選挙区制では、全国支持率の高さは勝利の十分条件ではありません。勝敗を分けるのは、接戦区に票がどれだけ集中するか、無党派がどの条件で動くか、そして投票率がどの層で上がるか。DSA(分布構造分析)は、支持や得票の分布を尖り・裾・多峰性として可視化し、支持が「薄く広く」なのか「勝てる帯域に厚い」のかを見極めます。支持率が高くても、分布の裾が安全区に偏れば議席には変換されません。
一方、DAG(因果グラフ)は“見かけの因果”を剥がします。年齢別支持の背後には、投票率、都市・地方の居住、所得や雇用、情報接触、争点の当事者性といった交絡が横たわる。解散のタイミングも同様です。経済指標や外交イベント、政策発表、メディア露出が同時に動く中で、「解散そのもの」の効果を他のショックと混同しない設計が不可欠になります。
DSA+DAGで占うと、問いはこう変わります。支持率は“どの分布”で、どの選挙区の接戦帯を厚くしているのか。動く無党派は、どの条件が揃ったときに投票に転ぶのか。解散は、その条件を強める介入になっているのか――それとも外部要因に埋もれるのか。吉凶の分かれ目は、支持率の高さではなく、因果の通り道が「議席」に向いているかどうかにあります。平均から分布へ、印象から構造へ。因果モデルは、解散判断の“勝ち筋”と“落とし穴”を同時に照らします。
1) 目的とEstimand(占う対象)を固定します
まず「吉凶」を1行で定義します。
- 主要アウトカム
:与党(または内閣支持基盤)の議席数(小選挙区・比例別でも可)
- 介入
:解散の実施(+タイミング:例「今月解散」 vs 「半年後」)
- Estimand(因果効果):

=「解散を選んだ世界」と「解散しなかった世界」の議席差
ここが揃うと、評論は「好き嫌い」ではなく「効果の推定」に変わります。
2) DAGテンプレ(ノード設計)
最低限、次のノード群を置きます(括弧は代表的な観測変数例)。
介入と結果
:解散(実施・タイミング)
:選挙結果(議席、得票率、勝敗)
主要な因果経路(媒介:M)
解散が結果に効くなら、途中で何かが動きます。
:投票率(全体・年齢別・地域別)
:無党派の投票先分配(浮動層のスイング)
:争点サリエンス(何が主要争点になるか)
:候補者・選挙区力学(候補者調整、接戦区の集中)
交絡(C:TにもYにも効く“混ざり物”)
ここを塞がないと、相関を因果と誤認します。
:政権状態(内閣支持・不支持、党支持、スキャンダル)
:マクロ環境(物価・賃金・景気、国際情勢、災害など外生ショック)
:選挙区構造(都市/地方、過去の得票分布、接戦度、人口動態)
:対抗側の状態(野党の候補者調整・分裂、連立の枠組み)
:調査・情報環境(メディア露出、SNS話題、世論調査モード差)
基本DAG(文字で表す骨格)
(支持率や経済が“解散判断”に影響)
(同じ要因が“選挙結果”にも影響)
(解散が投票率や無党派を動かし議席へ)
3) 調整セット(何をコントロールし、何をしないか)
ここが「相関→因果」を決める核心です。
まずやる:バックドアを塞ぐ(推奨の調整)
- 調整する(C):
内閣/党支持のトレンド、経済指標、外生イベント、選挙区構造、対抗側の状態、情報環境(最低限 proxy でも) - 調整しない(M:媒介):
投票率や無党派スイングは、解散の効果そのものの通り道なので、基本は調整しません(やるなら別Estimand=「直接効果」にします)。
これで「支持率が高いから勝つ」という相関の短絡を避けられます。
「支持率が高い“から”解散し、同時に勝ちやすかっただけ」という混同(交絡)を潰します。
4) DSA設計(“平均の支持率”を分布に分解して勝敗変換を点検)
DAGで構造を固定した上で、DSAで「議席に変換される形か?」を見ます。
可視化①:選挙区別の“接戦帯”分布
- 指標:与党(または主要党)の選挙区得票率分布
- 見る形:45–55%帯の厚み、裾の伸び、尖り
- 解釈(占いのルール)
- 接戦帯が厚い:小さな揺れで議席が大きく動く → 吉凶の振れ幅が大
- 安全区に尖る:票が積み上がっても議席は増えにくい → 凶寄り(変換効率が悪い)
可視化②:地域偏在(山がどこに立つか)
- 都市/地方、ブロック別に分布を並べる
- 解釈:支持が「増える場所」と「議席が増える場所」が一致しているか
可視化③:無党派の“分布分解”
- 「支持なし」を1つにせず、
常時無党派 vs 浮動無党派(直前変動しやすい層)
を分ける(代理変数でもOK) - 解釈:解散が動かすのはどちらか(動く層が多いほど“解散の効果”は出やすい)
可視化④:年齢別支持×投票率(ここで“見かけの年齢効果”を剥がす)
- 年齢別「支持」だけでなく、投票率で重み付けした分布を見る
- 解釈:若年支持が強くても投票に変換されなければ議席影響は小さい
5) 「吉と出る/凶と出る」を因果モデルで言い換えると
主観の代わりに、次の2条件で結論を出します。
- 条件A(DAG):交絡を塞いだ後も、
の道が太い
(解散が投票率・無党派・争点を動かす見込みがある) - 条件B(DSA):その動きが 接戦帯 と 議席増加が起きる地域に集中している
AもBも満たす → 吉
AはあるがBがない(安全区に偏る等)→ 凶
Aが弱い(解散しても何も動かない)→ 凶
Aは強いが不確実(接戦帯が極厚で多峰性)→ ハイリスク・ハイリターン
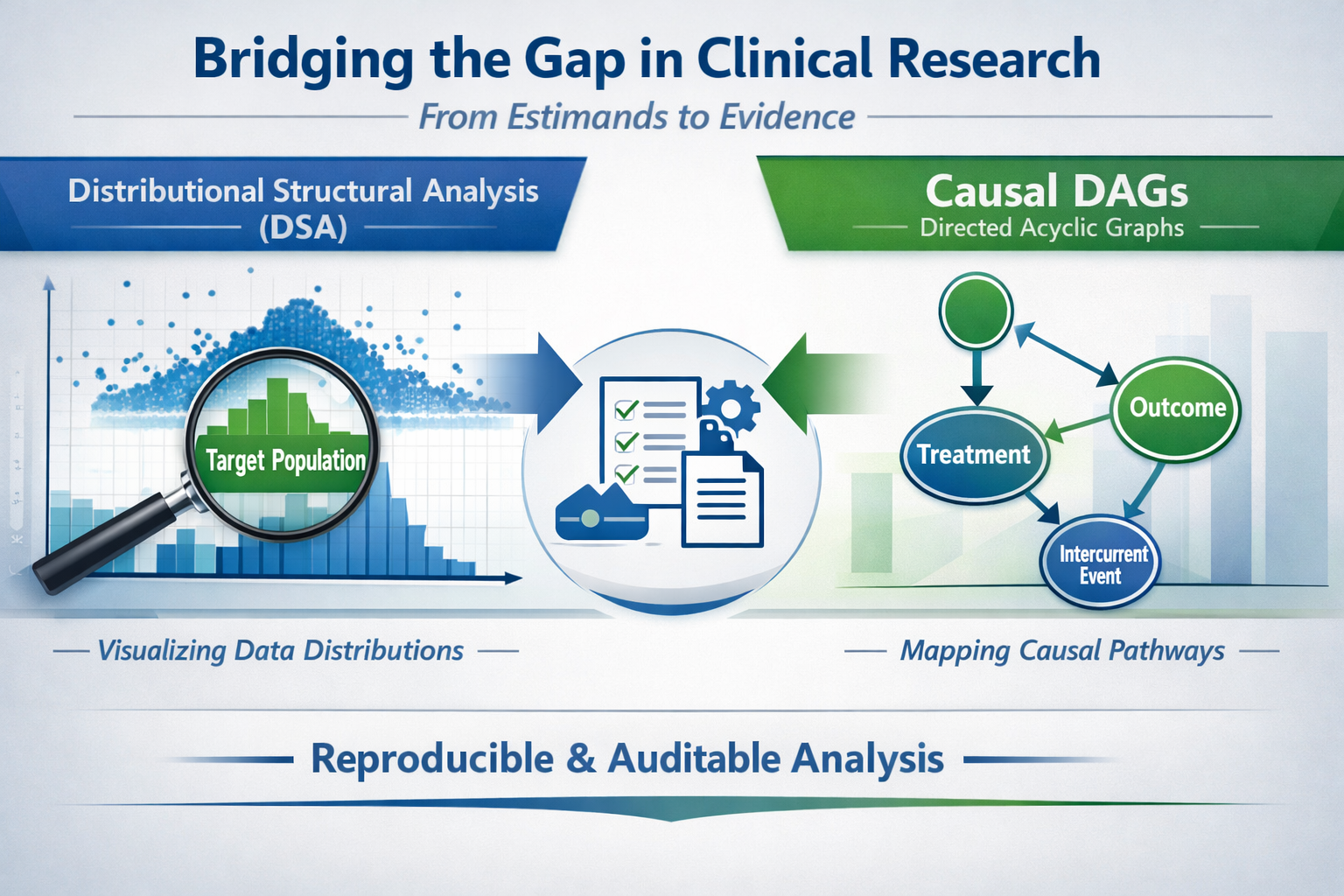
臨床試験やリアルワールドデータにおける*ESTIMAND(推定対象)を、単なる言葉の定義に留めず、実効性のある解析へと繋げる手法を解説します。従来の定義だけでは、集団の異質性や中間の事象(ICE)の扱いが曖昧になり、解析段階で妥当性が損なわれる課題がありました。この解決策として、データ構造解析(DSA)で母集団の分布を可視化して実体化し、因果グラフ(DAG)で介入構造と変数の関係を固定することを提唱します。これら二つの手法を組み合わせることで、推定対象をデータ上で正確に再現し、後付けの修正を防ぐことが可能になります。最終的に、エスティマンドを「概念」から、客観的で監査可能な「運用可能な設計図」へと変換することが重要となります。
*ミュートしています。

JAMAに掲載されたSMART-Cのメタ解析(JAMA 2025;7:e2520834)は、SGLT2阻害薬がベースラインeGFRやアルブミン尿(UACR)の程度にかかわらずCKD進行リスクを低下させ、ステージ4 CKDや微量アルブミン尿を含む広い範囲で腎アウトカム改善を支持する、と結論づけました。
しかし、一般化(条件撤廃)が成功するほど、臨床の意思決定は別の方向で難しくなります。エビデンス薬が増えるほど推奨は積み上がり、併存症の多い高齢患者に「ベネフィットがある薬剤を全て」適用すれば“Fantastic Infinity”になり得る──その危惧は本稿の核心です。
しかも、エビデンス薬同士の優先順位を示すhead-to-head試験は成立しにくい。結果として「投与しない勇気」という暗黙知に委ねられる局面が生じます。
ここで重要なのは、JAMAの統計アプローチが“弱い”のではなく、問いが違うという点です。SMART-Cは、層別(eGFR/UACRなど)で治療効果を推定し、逆分散加重で統合することで「平均として広く効くか」を強く示します。
ただし、次の意思決定──「誰に強く勧め、誰は慎重にし、誰は見送るか」──を作るには限界が残ります。理由はシンプルで、(1)層別解析は相互作用(効果修飾)の検出力が不足しやすく、「差が見えない=差がない」とは言い切れないこと、(2)eGFRやUACRをカテゴリ化することで連続的な非線形性や“カテゴリ内の異質性”が見えにくいこと、(3)逆分散加重で得られるのは基本的に“平均(サブグループ平均)”であり、もし真の世界にテイル(効きにくい/害が勝つ少数)があるなら、その構造は平均化で薄まることです。
この「平均の外側」を扱うために、DSA+DAGが解決策となる可能性があります。ここで必要なのは、新しい“推奨”ではなく、優先順位づけを支える説明可能な意思決定です。
DSA(分布構造分析)は、平均効果に回収されがちな反応の異質性を、分布の形として一次情報化します。たとえば同じ“有効”でも、(1)改善が厚い中心と、(2)効きにくいテイル(あるいは不利益が大きいテイル)が混在していないか、(3)二峰性(効く群/効かない群)が立っていないか、といった「適用の粗さ」を検知できます。平均の優越ではなく、“どこまで一般化してよいか”の境界条件を、データの形から提示するわけです。
またDAG(因果グラフ)は、その分布の形がなぜ生じるのかを因果経路として記述します。併存症、フレイル、併用薬、フォロー頻度、そして「処方する/しない」という選択自体をノードとして明示すれば、交絡・媒介・選択バイアスがどこに入り、何を調整すべきかが構造として見えるようになります。すると「この患者には使わない」という判断が、単なる経験談ではなく、反証可能な仮説(どの経路が不利益を増幅するか)として説明可能になります。
メタ解析が“条件撤廃”を推し進める時代に必要なのは、条件を外すこと自体ではなく、外した後に生じる優先順位の空白を埋めることです。DSAで“誰にどれだけ(形として)効くか”を示し、DAGで“なぜそうなるか(構造として)説明する”。この連結があれば、Fantastic Infinityを避ける「止めどころ」を、経験値ではなく監査可能な意思決定として提示できる可能性があります。
参考(背景論文):Neuen BL, Fletcher RA, Anker SD, et al; SMART-C. SGLT2 Inhibitors and Kidney Outcomes by Glomerular Filtration Rate and Albuminuria: A Meta-Analysis. JAMA. 2025 Nov 7:e2520834. doi:10.1001/jama.2025.20834.