LinkedInを見ていると、
「I’m excited to share that I’m starting a new position…」という投稿を頻繁に目にします。
新しい役職に就いたことを誇らしげに報告する投稿です。
もちろん、それ自体は素晴らしいことです。努力の結果であり、組織から評価された証でもあります。
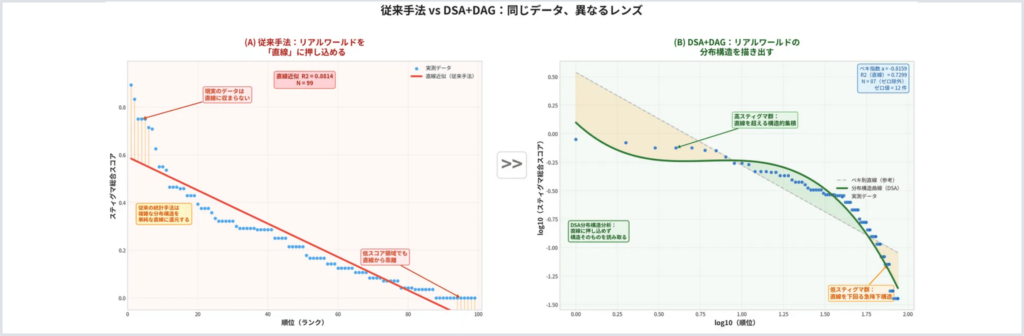
その前提に立ったうえで、少しだけキャリアを構造から見てみると、いま大きな変化が起きているように思います。
構造的に見ると、そこには一つの事実があります。それは、役職が変わっても、多くの場合組織の中の役割であることは変わらないということです。
課長、部長、VP、Head of ○○…。
肩書きは変わりますが、それは多くの場合、同じゲームの中でレベルが上がることを意味します。
これまでは、それで十分でした。企業という組織の中でキャリアを積み上げていくことが、最も安定した成功の道だったからです。しかし、ここに来て状況が少し変わり始めています。
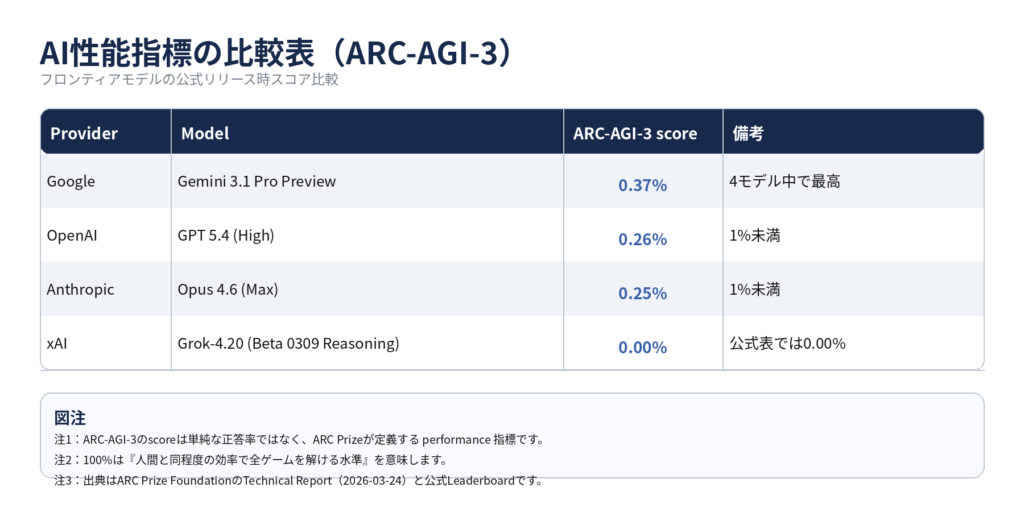
それは、AIの登場です。
AIは、これまで人間が担ってきた多くの知的作業を急速に置き換え始めています。資料作成、分析、翻訳、プログラミング、調査。かつては専門職の領域だった仕事も、AIによって再構成されつつあります。
つまり、私たちは今、キャリアの前提そのものが変わる時代に入りつつあるのかもしれません。これからは、その選択肢がよりはっきりと分かれていくように思います。
昇進は確かに重要な成果です。しかし同時に、これからの時代は新たな問いも生まれています。
AIが登場したことで、キャリアの見え方そのものが、静かに変わり始めているのかもしれません。