― 京都の男子行方不明事案が突きつけた「記録型社会」の限界と、DSA+DAGの可能性
京都府南丹市で小学生男児の行方不明が続いている事案では、4月上旬時点でも有力な直接手がかりが乏しく、報道では周辺の防犯カメラの少なさや、本人が携帯電話を持っていなかった可能性が捜索難航の要因として指摘されています。警察・消防・地域による大規模な捜索や情報収集が続いていますが、なお決定的な直接ログが見つかっていない、という構図です。
この事案を見て改めて浮かび上がるのは、現代社会が想像以上に「直接Log依存型」であるという事実です。
防犯カメラ映像、ドラレコ、携帯位置情報、目撃証言、Nシステム。現代の捜査や危機対応は、まずこうした「事件に直接つながる記録」を探しに行きます。実際、警察庁が整備しているNシステムも、通過する車両のナンバーを自動的に読み取り、手配車両と照合することで、重要犯罪や自動車関連犯罪の捜査を支援する仕組みとして位置づけられています。
これは極めて合理的です。
映像がある。ナンバーがある。位置がある。時刻がある。
そのとき初めて、捜査は「何が起きたか」を具体的に復元しやすくなります。
しかし同時に、この構造は大きな限界も抱えています。
直接Logがなければ、急に視界が悪くなるのです。
今回の事案でも、報道上の論点は繰り返し「どこかに映っていないか」「どこかに記録が残っていないか」「新たな情報提供はないか」に集中しています。これは裏を返せば、現代の危機対応が、強力である一方で、かなりの部分を“記録されていたかどうか”に依存していることを示しています。
ここに、ビジネス上も見逃せない本質があります。
この問題は、警察捜査だけの話ではありません。
企業経営でも同じです。
営業でも、製造でも、物流でも、セキュリティでも、組織運営でも、多くの現場は「直接Log」があることを前提に設計されています。
会議ログ、購買履歴、センサー値、アクセス履歴、通話記録、GPS、打刻、監視映像。
こうしたデータがあれば、事後検証はしやすい。異常も追いやすい。責任の所在も追跡しやすい。
しかし逆に言えば、ログが欠けた途端に、組織は驚くほど無力になることがあります。
ここで問うべきなのは、
「直接Logがないと何も分からないのか」
ということです。
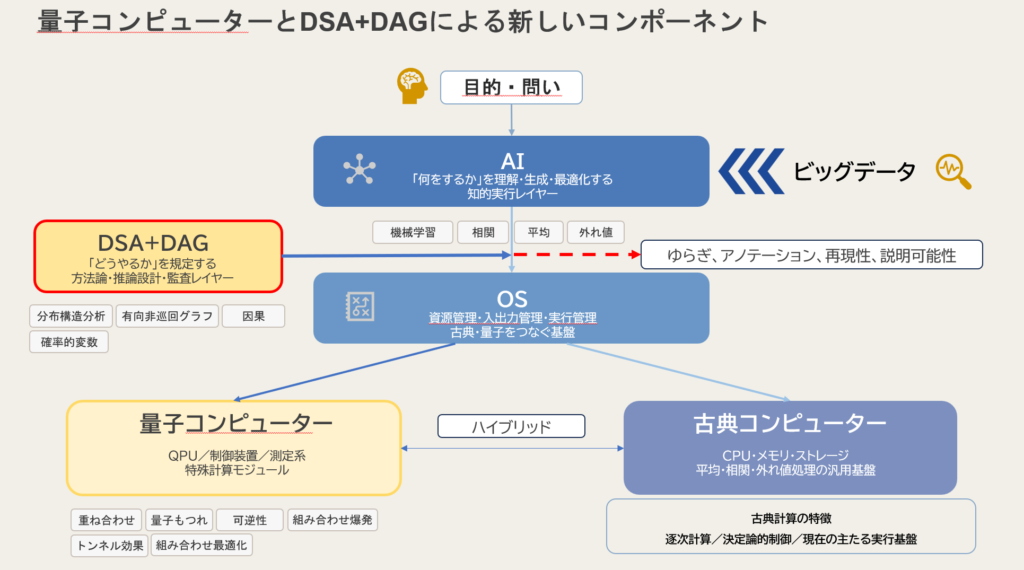
私は、ここにDSA+DAGの価値があると考えます。
DSA+DAGは、直接映像や直接記録そのものを代替するものではありません。
犯人の顔を映すわけでも、ナンバーを読み取るわけでもありません。
しかし、直接Logが不足している状況でも、なお分析可能な領域があります。
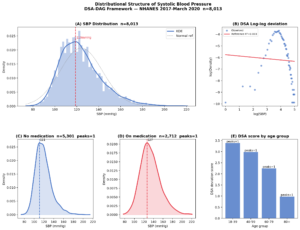
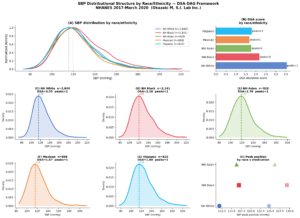
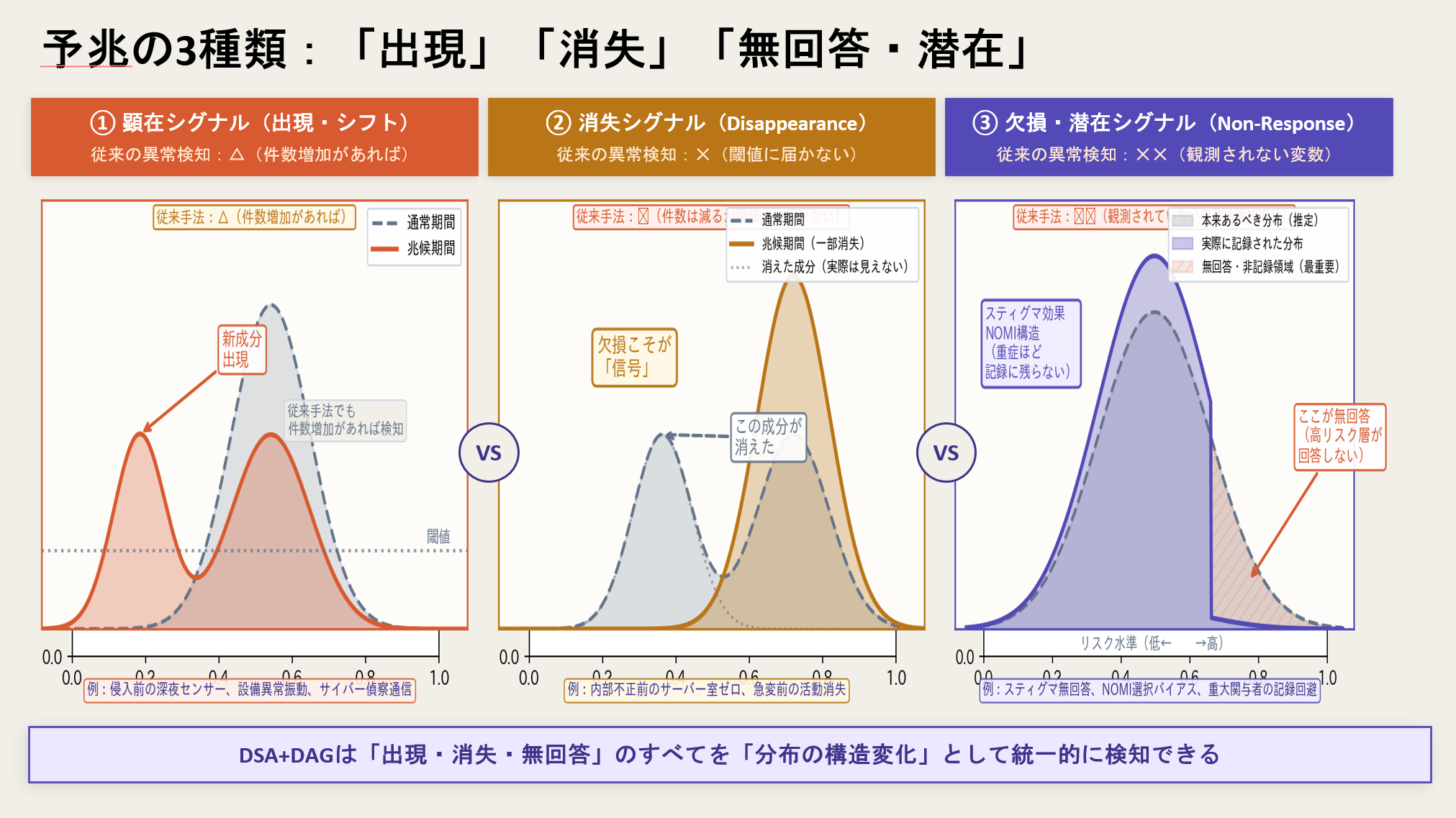
それが、分布構造の出現・消失・欠損です。
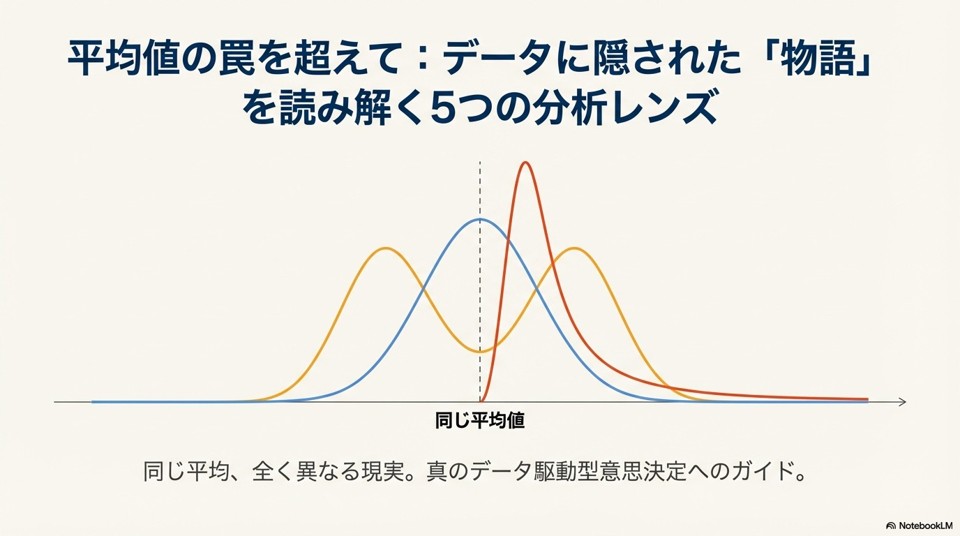
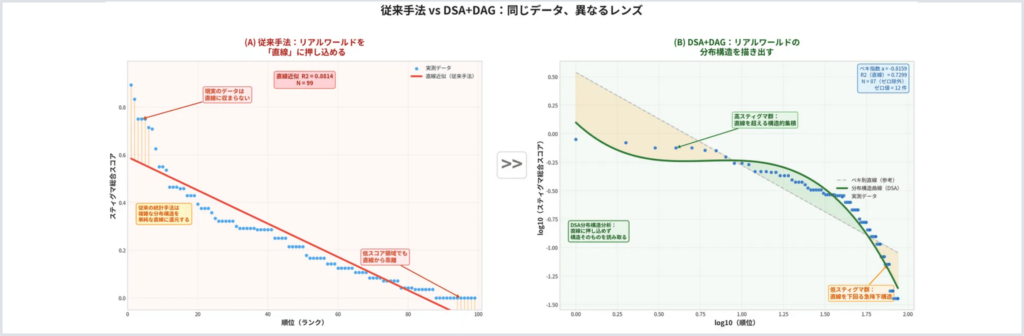
通常の分析は、記録されたデータの「値」を見ます。
しかしDSAは、その前に分布の形そのものを見ます。
何がどのくらい存在していたか。
どの時間帯にどのような流れがあったか。
どの地点でどういう密度になっていたか。
どの系列が自然につながっていたか。
そして、それがいつ、どこで、どのように崩れたかを見るのです。
たとえば、防犯カメラに「事件の瞬間」が映っていなかったとしても、だから情報がゼロとは限りません。
もし平時の地域における人流・車流・滞在・通過順序・観測頻度の分布構造が把握されていれば、当日のデータには別の意味が生まれます。
本来なら、ある時間帯に、ある地点群で、ある種の移動が観測されるはずだった。
ところが、その分布だけが不自然に薄い。
本来つながるはずの系列が、ある地点以降で急に途切れる。
逆に、平時には目立たない車両群や滞在パターンが局所的に出現する。
あるいは、「映っていない」はずの欠損が、単なる偶然では説明しにくい形で集中している。
このとき、DSAは「欠損」を単なる欠けたデータとは見ません。
欠損そのものを構造として読む可能性があります。
ここが重要です。
従来型の直接Log依存の世界では、「映っていない」は多くの場合「証拠不足」です。
しかし分布構造の視点からは、「映っていない」こと自体が、平時と比較されることで意味を持つ異常になり得ます。
つまり、
直接Logがないこと
と
構造上、何も分からないこと
は同じではありません。
この発想は、企業の現場でも非常に重要です。
たとえば製造業では、不良が出た瞬間の映像やセンサー記録がなくても、ライン全体の分布構造の崩れから、どの工程で異常が始まったかを推定できる場合があります。
営業でも、商談の録音がなくても、案件化率・接触間隔・失注時点・属性分布の変化から、どこで異常な離脱が起きているかは見えてきます。
サイバーセキュリティでも、侵入そのものの決定的ログが欠けていても、平常時のアクセス分布、時間帯、権限移動、通信量の構造変化から、異常の輪郭を浮かび上がらせることは可能です。
つまり、DSA+DAGの価値は、「記録された事実を確認する」ことではなく、
記録が不完全でも、平常構造からの逸脱を把握し、因果候補を整理できること
にあります。
ここでDAGが効いてきます。
DSAが見つけるのは、あくまで構造の歪みです。
その歪みが見えたとしても、次に必要なのは、
「それは何が原因なのか」
「どこが起点で、どこが結果なのか」
「単なる観測不足なのか、それとも行動変容なのか」
を整理することです。
DAGはこのとき、異常を因果仮説として並べ替える役割を果たします。
たとえば、ある地点以降で観測が急減したとして、それは
- 単純にカメラ密度が低かっただけなのか
- 通常ルートから逸脱した移動が起きたのか
- 途中で第三の介入要因が入ったのか
- 先行する別の行動変化の結果として欠損が生まれたのか
を、変数の関係として仮説化していくことができます。
ここで初めて、直接Logの不足を、分析上まったくの空白にせずに済むのです。
もちろん、過信してはいけません。
DSA+DAGは万能ではありません。
基礎データが極端に少なければ、何も読めません。
平時データがなければ、「異常」と比較する基準もありません。
また、DSA+DAGだけで犯人特定や事件解決が完結するわけでもありません。
最終的な特定や立証には、やはり防犯映像、物証、証言、追跡データなどの直接証拠が必要です。
それでもなお、価値があります。
なぜなら現実の現場では、いつも完全なログが揃うわけではないからです。
むしろ本当に困るのは、
直接Logがないときに、組織が思考停止すること
です。
「映っていないから分からない」
「ログがないから追えない」
「証拠がないから手が打てない」
この思考は、捜査でも経営でも危険です。
本当に必要なのは、直接Logがあるときだけ機能する仕組みではなく、
直接Logが欠けていても、残された分布構造から次の一手を考えられる仕組み
です。
今回の男子行方不明事案は、その意味で、極めて重い問いを社会に投げかけています。
私たちは、防犯カメラを増やせば安心なのか。
記録装置を増やせば十分なのか。
Nシステムやセンサーを増設すればそれで解決なのか。
確かにそれらは重要です。実際、Nシステムのような自動車ナンバー自動読取システムは、手配車両の発見や車両利用犯罪の捜査支援に大きな意味を持っています。
しかし、本質はそこだけではありません。
記録装置を増やすだけでは、「何かがおかしい」を読む力までは手に入りません。
必要なのは、直接Logを集める力と、直接Logが足りないときに構造を読む力の両方です。
私は、DSA+DAGはこの後者を担う技術になり得ると考えています。
それは、事件後に犯人を言い当てる魔法ではありません。
しかし、何も映っていないように見える場所から、
何も残っていないように見えるデータから、
本来あったはずの構造、本来なかったはずの歪み、本来偶然では済まない欠損を見つけ出す。
その結果として、
- 捜索・調査の優先順位を絞る
- 異常地点を再点検する
- 追加取得すべきデータを特定する
- 人が見るべき場所と時間帯を絞る
- 「情報がない」状態を「仮説が立つ」状態に変える
ことができる可能性があります。
これは、防犯・警備だけの話ではありません。
企業のリスク管理、設備保全、物流異常、医療安全、品質保証、営業管理、サプライチェーン監視。
あらゆる領域で、「直接Logがなければ分からない」という壁は存在します。
そしてその壁を越える鍵は、個々の記録をさらに増やすことだけでなく、分布構造そのものを読む分析思想にあります。
今回の事案が教えているのは、
「見えていないから何もない」のではなく、
「見えていないものにも、構造は残る」
ということかもしれません。
直接Logの時代は、まだ終わりません。
むしろ今後も重要性は増すでしょう。
しかし、直接Logだけに依存する時代は、そろそろ限界です。
これから必要なのは、
記録を集める社会から、
構造を読む社会への進化です。
DSA+DAGは、その入り口に立つ技術だと私は考えています。