

自民党が衆院選で圧倒的多数を確保した。この出来事は、単に「人気が戻った」「政策が刺さった」と平均的な現象ではありません。ネットが作り出した雰囲気などと片付けていては本質を見失います。
今回の選挙結果は、与党が下院で大きな優位(3分の2規模)を得た、歴史的な“地殻変動”です。ここで起きているのは、支持率の上下という“平均”ではなく、社会の意思決定がどの層で、どの経路で、どの速度で動いたのかという「構造」の変化です。
同じ構造変化は、私たちの周辺でも露骨に進んでいます。アクセンチュアは、昇進にAIツールの“定常的な利用”を結びつけ、利用状況を評価に織り込む動きが報じられました。これは「全員の生産性が少し上がる」という話ではありません。AIを使う人だけが上方へ伸び、使わない人との間に“分布の差”が開くということです。平均値は、その差を隠します。
クラウドワークスの決算でも、利益の落ち込みや見通しの不確実性が示され、構造改革・投資・事業再編など複数要因が絡む局面であることが読み取れます。「AIのせいで儲からなくなった」と単因で語るのは簡単ですが、現実は要因が絡み合うネットワークです。ここでも必要なのは、“平均の増減”ではなく「どこで歪みが生まれ、どこがボトルネックで、どこが介入点か」という構造認識です。
要するに、これからのリアルワールドは「平均との差」では動きません。重い尾(勝者側の伸び)と、二極化と、連鎖で動きます。だから必要なのは、意識改革という精神論ではなく、見方の改革です。
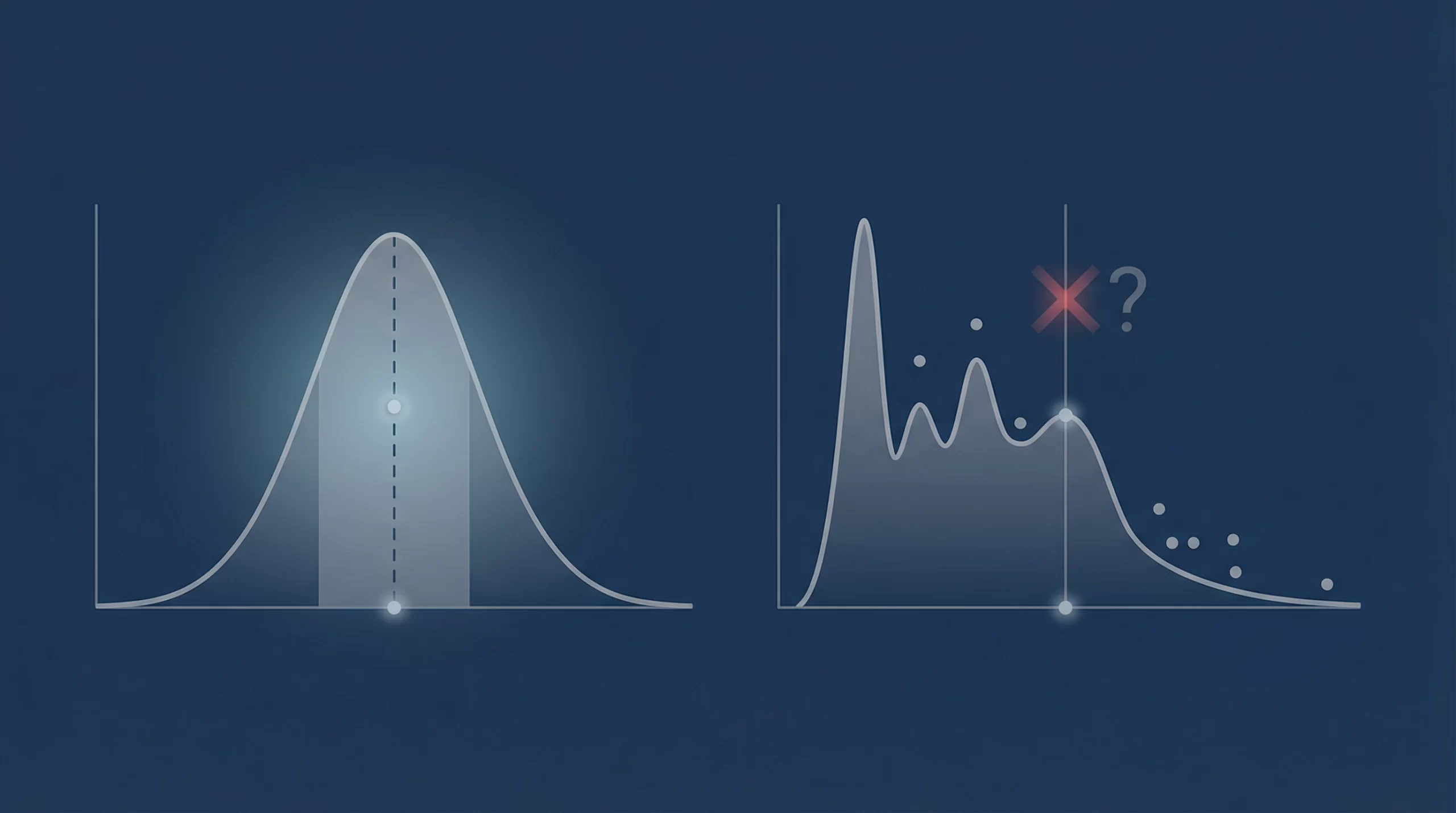
DSA+DAGが外れ値を産まず、特異点を見つける新しいアルゴリズムであることのる価値もそこにあります。派手な技術論ではなく、現実を「分布(どこが伸びて、どこが沈むか)」と「因果(なぜそうなるか)」の両方で捉える——その“読み方”が、政治や産業、医療、キャリアにも、そのまま効いてくる時代に入っています。

現代のビジネスにおいて、データ駆動型の意思決定は当然のこととして受け入れられています。ところが、私たちが使い慣れたその手法には、実は大きな落とし穴が潜んでいます。
それは、分析の過程に分析者の「恣意的な仮定」や前提がフィルターとして挟まり得るという点です。
「点」で測る従来法、「地図」を描く新手法
例えば広告施策の効果検証として、広告を「打った群」と「打たなかった群」の購買率を比較し、その「差」を測定るケースを考えてみます。これは、特定の施策が「効いたか、否か」という“点”の検証には適しています。
しかし、現実の市場はそれほど単純ではありません。
多くの場合、購買行動には認知、価格、広告チャネル、さらにはその時の心理状態といった無数の変数が複雑に絡み合っています。にもかかわらず、それらを「平均」という指標に集約し、計算を成立させるために、前処理やモデル仮定、欠測処理などを積み重ねがちです。
その結果、データが本来持っていた「生の声」が、分析者の意図(あるいは都合の良い前提)によって塗りつぶされてしまうことがあります。そもそも「購買行動を動かすKey Driverが広告である」という前提自体が、検証されないまま置かれてしまうケースも少なくありません。
構造から「沈黙の理由」を読み解く
これに対し、DSA(分布構造分析)+DAG(有向非巡回グラフ)によるアプローチは、恣意的な決め打ちを減らし、前提を“見える化して監査可能にする”ための方法です。いわば「ビジネスの構造図(地図)」を描き出す作業と言えます。
まずDAGを用いて、変数間の因果関係を論理的に可視化します。どの要因がどのルートで結果に影響しているのかを整理し、交絡・媒介・独立といった役割の違いを明確にしたうえで、必要な調整方針(どれを調整し、どれを調整しないか)を固定します。
そのうえでDSAにより、データの「分布全体」がどのように動いているかを解析します。
この手法の真骨頂は、従来「ノイズ」や「欠損」として捨てられていた情報に、構造的な意味を見出す点にあります。従来法では単なる欠測として処理されたデータも、DSA+DAGで捉え直すと、欠測そのものが「どの条件下で起きるのか」という構造を示している可能性があります。
「平均値の差」だけを追っていては、一生たどり着けない種類の発見です。
「恣意性」を脱ぎ捨て、真のレバーを見つける
モデルにデータを合わせるのではなく、データが語る構造を起点にモデル化する。このアプローチによって私たちは初めて、「広告が有効か否か」という二択を超えて、「何が顧客の購買行動のドライブになるのか」という、ビジネスを動かす真のレバー(重要因子)に近づけます。
「恣意的な分析」から「構造的な洞察」へ。データ駆動型経営の次なるステージは、平均という幻想に寄りかかるのではなく、複雑な現実をそのまま扱うところから始まります。
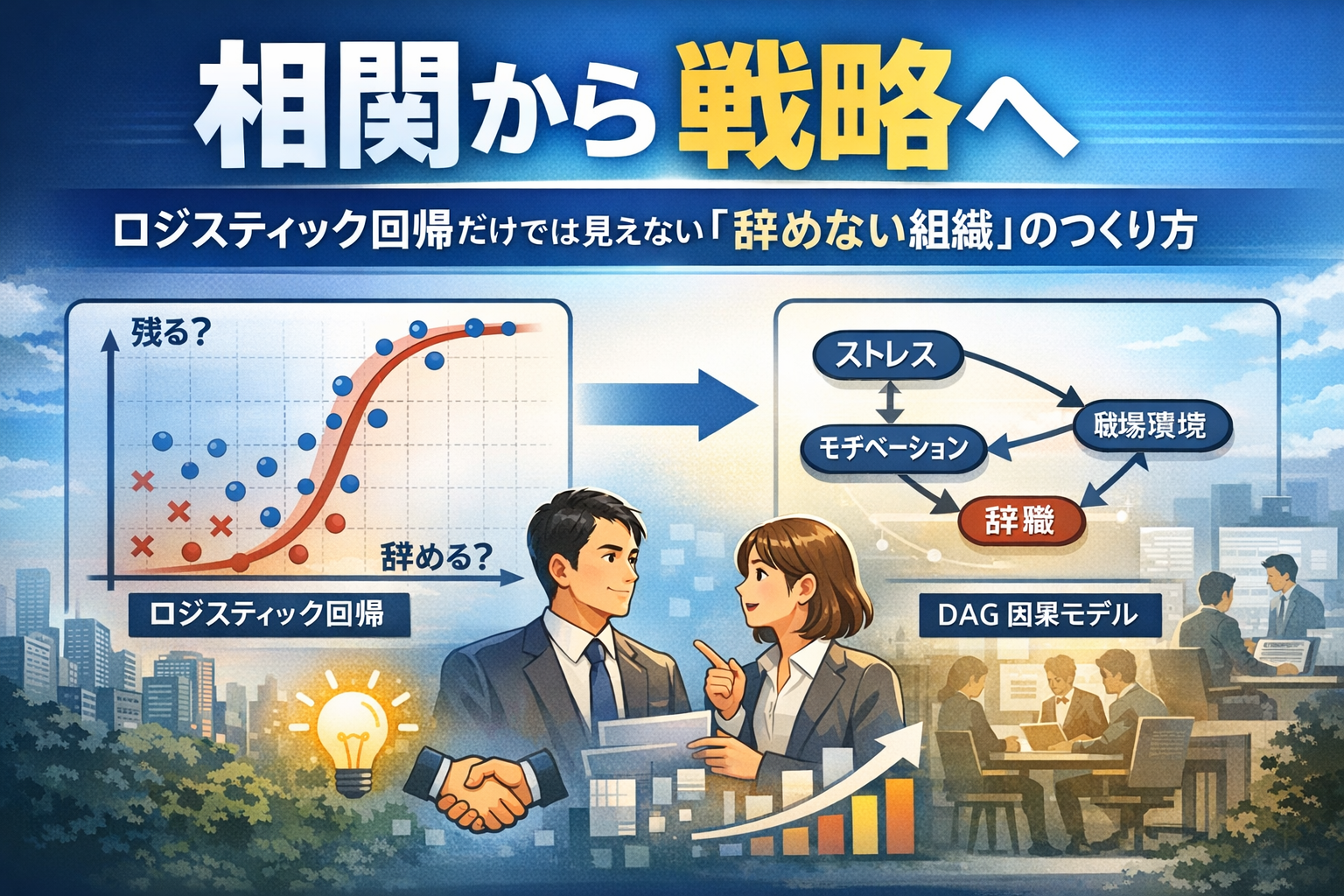
ロジスティック回帰は、人事データ分析の“入口”としてとても便利です。残業が多い、評価が低い、異動が多い、通勤が長い――こうした変数を入れれば、「辞めた人に多い特徴」や「辞めやすい人の傾向」はかなりの精度で見えてきます。ここで多くの人が「原因が分かった」と思ってしまいますが、実はそれは半分だけ正解です。ロジスティック回帰が教えてくれるのは、基本的に“相関”だからです。
相関の怖いところは、「当たって見えるのに、打ち手が外れる」ことです。たとえば「残業が多いほど退職が増える」という結果が出たとします。では残業を減らせば辞めなくなるのでしょうか。必ずしもそうとは言えません。部署が炎上している、上司のマネジメントが悪い、役割が曖昧で揉めている――こうした“共通の原因”が、残業も退職も同時に押し上げている可能性があるからです。この場合、残業は原因というより「炎上の症状」に近く、残業だけ減らしても根本原因が残れば退職は減らない、ということが起こり得ます。
ここで威力を発揮するのがDAG(因果ダイアグラム)です。DAGは「どの変数がどの変数に影響しているか」を矢印で描き、相関ではなく因果の筋道を固定します。ポイントは、回帰式そのものを賢くすることではありません。DAGによって「回帰に入れるべき変数」と「入れてはいけない変数」を決められることが価値です。例えば、原因の共通項(交絡)は調整すべきですが、施策の途中にある結果(媒介)をうっかり調整すると“施策の効き目”を自分で消してしまいます。また、複数要因の合流点(コライダー)を調整すると、存在しなかった関係を人工的に作ってしまうことがあります。ロジスティック回帰が「数字を出す装置」だとすれば、DAGは「数字の出し方を間違えないための設計図」です。
この設計図を持つと、「辞める人の特徴」から一歩進んで、「何を変えれば辞めにくくなるか」という問いに近づけます。たとえば介入を一つ定義します。残業削減、1on1頻度の増加、配置転換、役割の明確化、評価の透明性向上――どれでも構いません。次にDAGで、その介入が退職に届く経路と、同時に介入にも退職にも影響する交絡要因を整理します。最後に、その設計図に従ってロジスティック回帰(または時系列なら離散時間ハザード)を組めば、「介入した場合に退職確率がどれだけ変わる見込みか」という“打ち手の推定”に変わります。つまり、分析の成果が「当てる」から「動かす」へ変わるのです。
もちろん、DAGを描けば魔法のように正解が出るわけではありません。観測できない要因は残りますし、退職は確率現象なので個人を確定的にコントロールすることもできません。それでも、ロジスティック回帰だけで陥りがちな「相関を原因と誤認し、施策が外れる」という失敗は大きく減らせます。人事データ分析に求められるのは、説明のうまさではなく、現場で再現される意思決定です。その意味で、DAGは“分析を意思決定の道具に変える”ための、最も費用対効果の高い追加パーツだと言えます。
退職分析をやるなら、まずロジスティック回帰で地形図を描く。そして「どうすれば辞めないか」を知りたいなら、DAGで戦場のルールを固定する。相関の地形図に、因果の設計図を重ねたとき、分析は初めて“実行可能な戦略”になります。
通常の目標管理はこう考えます。
〇〇をやれば、頑張れば成功する
しかしDAGで見ると、中心(ドラフト8球団)に
外周から直接入る矢印に直接的な因果変数は存在していません。
外周(習慣・行動)
↓
媒介(能力・評価・状態)
↓
アウトカム
つまり、
行動 → 媒介 → 結果
です。
2️⃣ 媒介の数が“構造の厚み”になる
ここが極めて重要です。
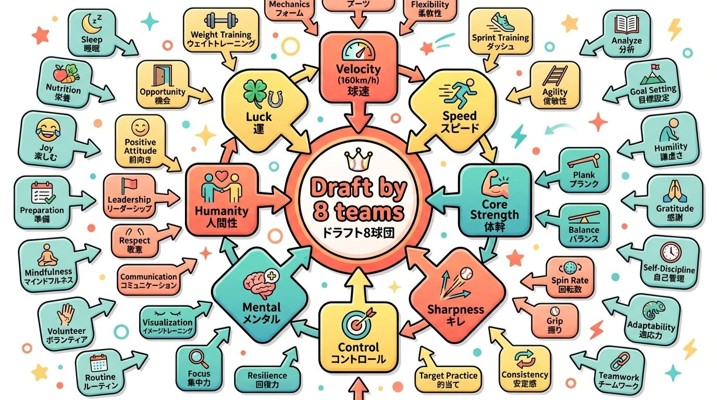
中心に近い8つのエレメント(球速、コントロール、キレ、メンタル、人間性、運など)は
結果を決める“媒介変数”
です。
そして外周は
媒介を動かす“因果変数”
になります。
成功確率は、
- 媒介の数が多いか
- 媒介の質が高いか
- それぞれに複数の因果が入っているか
で決まります。
3️⃣ レバレッジの本質
仮に球速という媒介が1つしかなく、
その球速を高める因果が1本しかなければ、
構造は脆弱です。
しかし実際のマンダラは違います。
球速に対して:
- 体づくり
- 下半身
- 体幹
- 可動域
- フォーム安定
と複数の因果が入っています。
これは
冗長性(robustness)を持つ構造
です。
4️⃣ 本当に面白いのはここ
目的達成に直結する因果はない
これは極めて重要です。
成功は「直接打つ矢」ではなく、
媒介の総合値
として現れます。
つまり、
- 行動は媒介を高める
- 媒介が結果を押し上げる
この二段階構造です。
5️⃣ ビジネスへの翻訳
例えば売上。
売上に直接効く因果はない。
広告 → 売上
は幻想です。
実際は:
広告 → 認知(媒介)
認知 → 信頼(媒介)
信頼 → 問い合わせ(媒介)
問い合わせ → 受注(媒介)
受注 → 売上
です。
売上に直接効くのではなく、
媒介を積み上げている。
6️⃣ マンダラDAGの核心
成功とは
媒介の数 × 媒介への因果の数 × 構造の整合性
で決まる。
ここが構造分析と因果推論が交差する地点です。
7️⃣ さらに一段深い話
媒介が8つあるということは、
どれかが落ちても全体が崩れない。
つまりこれは
分散型成功モデル
です。
逆に、
1つの媒介(例:才能)だけに依存すると、
構造は崩れやすい。
8️⃣ DAGの視点
DAG的視点では
- 因果の本数
- 媒介の厚み
に注目します。
多くの人は
「何をやるか」
に注目します。
しかし本質は
媒介を増やせているか?
です。
ここからさらに進むと、非常に面白い問いが出ます。
- 媒介は8個が最適なのか?
- 媒介の相互作用(交互作用)はどう描くか?
- 媒介間の競合(トレードオフ)はあるか?
- 媒介の重要度をどう定量化するか?
これは完全に構造分析×因果推論の世界です。
― 構造分析(DSA)と因果推論(DAG)で読む“勝てる設計図”
大谷翔平のマンダラチャートが世界のデータサイエンティストに分析されているそうです。なぜなら、あの1枚は“努力のチェックリスト”ではなく、成果を生み出す構造そのものを描いた「設計図」だからです。
1. まず前提:目標は「分解」ではなく「構造化」する
多くの目標設定は、こうなりがちです。
- 目標を決める
- 行動を増やす
- 頑張る
- 結果が出たら正解、出なければ根性不足
これだと、結果が出ても出なくても、説明が“後付け”になります。
つまり再現できません。
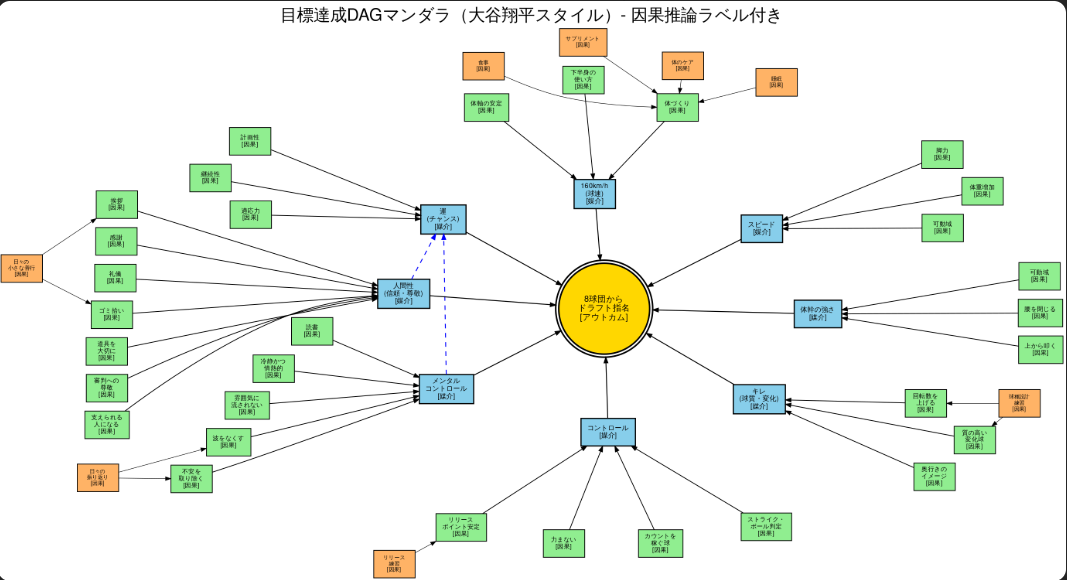
一方、マンダラチャートの中心には「ドラフト8球団」が置かれ、その周囲に「球速160km/h」「コントロール」「キレ」「体づくり」「メンタル」「人間性」「運」などが並びます。
ここで起きているのは、分解ではなく構造化です。
言い換えるなら、
「結果を生む要因の仮説を、全体構造として配置している」
2. 構造分析(DSA):成果は“能力”ではなく“構造”で決まる
構造分析で見るポイントは、「項目の良し悪し」ではありません。配置と階層です。
マンダラは三層構造になっています。
- 中心(成果):ドラフト8球団
- 第一層(直接要因):球速、コントロール、キレ、メンタル等
- 第二層(基盤要因):食事・睡眠・体幹・下半身・習慣・人間性
この三層はビジネスで言えばこうです。
- 売上(成果)
- 価格・品質・営業力(直接要因)
- 組織文化・採用・仕組み・習慣(基盤要因)
多くの会社が「売上が伸びない」と言いながら、第一層だけをいじります。
施策(広告、営業、キャンペーン)です。
でも本当は、成果を押し上げるのは第二層、つまり基盤構造です。大谷チャートが面白いのは、球速と同じ盤面に「ゴミ拾い」「あいさつ」「感謝」「信頼される人間」といった“基盤”を置いている点です。
これは精神論ではありません。構造分析的には、
「成果を決めるのはパフォーマンスだけでなく、パフォーマンスが生まれる土台構造である」
という意思表示です。
3. 因果推論(DAG):なぜ「ゴミ拾い」がドラフトに繋がるのか
ここからが因果推論(DAG)の出番です。
「ゴミ拾いがドラフトに関係あるの?」
普通はそう思います。
しかしDAG的には、直接効果でなく間接経路(媒介)や環境経路を疑います。
たとえば因果の経路はこう描けます。
- ゴミ拾い → 人間性の評価 → 指導者の信頼 → 練習機会・推薦 → ドラフト
- あいさつ → チーム内関係 → 情報や助言の流入 → 成長速度 → パフォーマンス → ドラフト
- 感謝 → 支援者の増加 → 環境の改善 → 継続性 → パフォーマンス → ドラフト
つまり「ゴミ拾い」は、球速を上げる薬ではありません。環境と支援の因果構造を設計する介入なのです。
ビジネスに置き換えると分かりやすいです。
- 5S(整理整頓)
- 挨拶
- 報連相
- 期限厳守
- 誠実な対応
これらも売上を“直接”作りません。
でも、信頼・協力・紹介・継続という因果経路を通じて、結果的に売上に効きます。
DAGで読むと、マンダラは
「見えない因果経路まで含めて、勝ち筋を設計している」
ということになります。
4. この1枚が“データサイエンティスト向き”な理由
データサイエンティストが興奮するのは、ここが揃っているからです。
- 目的(アウトカム)が中心に固定されている
- 要因(説明変数候補)が網羅されている
- 階層(直接要因/基盤要因)が分かれている
- 因果(媒介・環境・評価の経路)が暗黙に含まれている
これは統計の世界で言えば、
- KPIツリー
- 因果ループ
- ベイジアンネットワーク
- 介入設計(policy design)
の“手書き版”です。
5. ビジネスへの教訓:成果を出す人は「努力」ではなく「構造」を作る
結論はシンプルです。努力とは“量”ではありません。努力とは“構造への投資”です。
大谷チャートが示しているのは、
- 何をやるか(施策)ではなく
- どういう構造なら勝つか(設計)
です。
だからこそ、これは目標管理シートではなく、成果を再現するための構造モデルなのです。
そして、構造分析(DSA)と因果推論(DAG)を使えば、私たちはこの1枚を
①感動話でも、②根性論でもなく、③再現可能な意思決定の言語
として読み解けます。
まとめ:マンダラは「意思決定の可視化」である
「目標を立てる」のではなく、「成果が生まれる構造を定義する」。
さらに、「その構造を因果でつなぐ」。
この2つが揃ったとき、初めて目標は“達成可能な設計”になります。
大谷翔平マンダラの価値は、ここにあります。
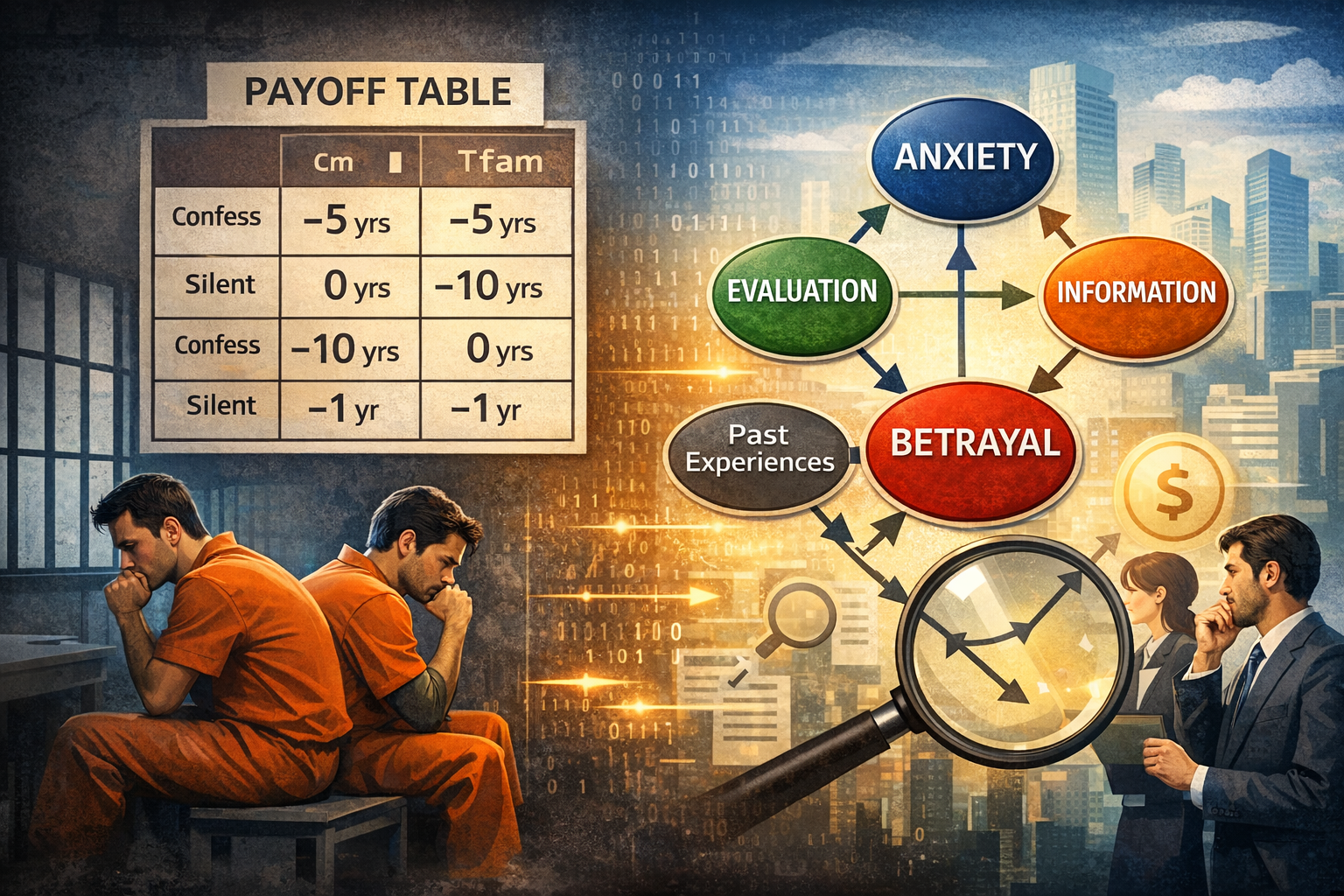
分析ゲーム理論に出てくる、囚人のジレンマの「理想解」は、2人とも黙秘するです。けれどリアルワールドでは、各人が自分にとって一番魅力的な選択肢を選んだ結果、協力した時よりも悪い結果を招いてしまうことが多くなります。
理由は単純で、当事者は俯瞰して利得表(ルールの全体像)を見られないからです。相手が黙秘する保証もない。自分が黙秘した結果だけが損になる恐怖が勝つ。結果として、裏切り(自白)に流れやすい。ここまでは教科書どおりです。
しかし、現実が難しいのはここからです。現実の「ジレンマ」は、利得表が固定されていません。上司の評価制度、監査の有無、罰の運用、情報の偏り、過去の人間関係、組織文化、そして“空気”までが、黙秘と自白の価値を日々書き換えています。つまり、私たちが対峙しているのは「利得表」ではなく、「利得表を生成する構造」です。
そこで効くのがDAG(因果グラフ)です。DAGは、当事者が見落としがちな“裏側の配線”を可視化します。たとえば「相手を信用できない」という心理は、単なる性格ではありません。過去の裏切り経験、評価制度、情報共有の欠如といった要因により生まれる“結果”かもしれない。ここを交絡として置けると、「裏切りが多い組織」と「裏切りが多い人」を混同せずに済みます。
さらにDAGは、媒介(メディエーター)を置けます。制度→不安→裏切り、のように、意思決定の途中にある心理や認知を変数として扱える。ビジネス現場で重要なのは、「裏切るな」と説教することではなく、「不安が裏切りを合理化する構造」を断つことです。たとえば監査の設計、反復取引の仕組み、情報の透明性、フェアな評価指標――こうした介入可能なノードが見えてきます。
そして一番の落とし穴が、固定(条件づけ)です。現場のデータは往々にして偏ります。クレームが出た案件だけ、退職者だけ、炎上したプロジェクトだけ。そこだけを見て「人が悪い」「現場が弱い」と結論づけると、選択バイアスで因果が逆転します。DAGは「どこに条件づけてしまったか」を明示できるので、“反省会をやった気になって終わる”を減らせます。
利得表を知っている観察者は「協力しろ」と言えます。でも当事者は、ルールが見えず、信頼も担保されず、罰の運用も不確実な中で意思決定しています。だから黙秘しない。裏切りはモラルの欠如というより、構造の帰結です。 ビジネスの本質も同じです。現場に「協力しろ」「顧客第一」「挑戦しろ」と言うだけでは変わりません。協力が合理的になる構造を設計しない限り、ジレンマは再生産され続けます。利得表を暗記するより、利得表を生む因果を描く。リアルワールドを知ることは、その構造を見抜くことです。

「ビッグデータ」や「AI」という言葉が飛び交う現代において、私たちの意思決定の根拠となる「データ解析」そのものが、いまだ旧時代の制約に縛られていることに、どれほどのリーダーが気づいているでしょうか。
多くの現場では、膨大なリアルワールドデータ(RWD)を扱いながら、最終的には「平均値」や「中央値」といった1次元の数値に情報を凝縮して判断を下しています。しかし、AIが複雑な非線形性を描き出すこの時代において、これまでの標準的な統計手法はもはや「推奨」ではなく、克服されるべき「限界」となっています。
いま、真のリアルワールドエビデンス(RWE)を構築するために不可欠なのが、DSA(分布構造解析)+DAG(有向非巡回グラフ)という新しい解析アーキテクチャです。
1. 「情報の蒸発」を許さない:1次元から2次元への転換
従来の解析は、いわば「計算機が非力で、人間が紙とペンで理解できる範囲」に最適化された、情報の削ぎ落とし(抽象化)の歴史でした。多次元で複雑なデータを1次元の点に丸める過程で、データの持つ「多様性」や「微細なゆらぎ」という最も価値ある情報は霧散してしまいます。
これに対し、DSA(分布構造解析)はデータを省略せず、多次元的な「分布の形」をそのまま診断します。これは、情報を「点」ではなく、広がりを持った「構造(2次元)」として捉え直す行為です。AIの圧倒的な計算力を活かし、データの「現実」を損なうことなく保持するこのアプローチこそが、AI時代の解析の出発点となります。
2. 「主観の暴走」を制御する:説明責任の再定義
現在、臨床研究のトレンドである「estimand(何を推定するか)」は、解析プロセスを透明化する優れた枠組みです。しかし、そこには大きな落とし穴があります。プロセスが説明可能(Explainable)であっても、それが研究者の「主観的な仮定(言い訳)」の積み重ねであれば、結論が正しいとは限らないのです。
そこで必要になるのが、DAG(有向非巡回グラフ)による構造化です。 研究者の因果仮定を2次元のネットワーク図として外部化し、それをDSAで得られた「生データの現実」と強制的に照合(監査)する。この「理論と現実のダイレクトな対話」こそが、専門家の暗黙知を民主化し、真の客観性を担保します。
3. 「監査可能性(Auditability)」という新しい信頼
AI時代のビジネスにおいて、最も重要なのは「正解」を語る魔法ではありません。「どう考えてその結論に至ったか」を、第三者が検証可能な形で残す「監査可能性」です。
DSA+DAGのワークフローは、単なる計算手法ではありません。
- 膨大なデータからAIが因果の候補を絞り込み、
- 人間の主観がデータの現実と矛盾していないかを自動で点検し、
- そのすべてのプロセスを「誠実な痕跡」として記録する。
このアーキテクチャを実装することではじめて、RWDは、規制当局や社会を納得させる揺るぎない「証拠(RWE)」へと昇華されます。
結論:アーキテクチャの転換が、未来を創る
正規分布や線形モデルという「理想」にデータを当てはめる時代は終わりました。 データの「現実」に手法を合わせ、その構造を監査可能にする。 DSA+DAGは、AI時代のデータ利活用において、もはや選択肢の一つではありません。信頼に足る意思決定を行うための、必須のインフラ(アーキテクチャ)なのです。

estimandのセミナーに参加しました。参加者から質問が出るたびに、解答には新しい情報やスキルが追加され、話がどんどん難解に、そして深く潜り込んでいく、そんな感覚を覚えました。限界や課題の話で終わるのではなく、あらゆる疑問に対してさらに高度な解答が返ってくる。その結果理解が追いつかない・・・。
では、estimandは「破綻のない完璧な理論」なのでしょうか。
答えは、完璧ではありません。ただし、完璧に“見えやすい”仕組みを持っています。estimandは「完璧だから難しい」というより、「破綻しないように設計されている」ために、質問を受けるたびに前提(定義・仮定・適用範囲)を追加していく構造になっています。だから解答が毎回“深く潜る”方向に伸びるのです。
estimandは「解析手法」ではなく「問いの仕様書」
estimandは、解析テクニックそのものではありません。むしろ“問いの仕様書”です。
質問が飛ぶということは、仕様書の曖昧さが露呈している、ということでもあります。
- どの効果を言いたいのか(治療方針込みか/仮想世界か)
- どのICEをどう扱うのか(中断、救済治療、併用薬など)
- 何を母集団とするのか(誰に一般化するのか)
- 何が観測され、何が欠測か(欠測メカニズム)
- どこまでが識別可能で、どこからが仮定か
こうした論点を、質問のたびに「仕様追加」していく。質問が鋭いほど、仕様追加は増えます。
「完璧に見える」のは、整合性を守るために条件が増えるから
estimandは議論が破綻しないように、言葉を定義し、対象を限定し、仮定を明示し、主張の射程を狭めることで整合性を保ちます。
だから“完璧”というより、整合性を守るために条件が増え続ける。これが難解さの正体です。
そして、ここが重要です。estimandには「限界」と「課題」があります。
- 未測定交絡を消すことはできない
- 欠測を魔法のように埋めることはしない(結局は仮定の問題)
- DAGや臨床知識の主観を排除できない
- 1つの正解を与えるというより、問いを複数に分解する
- 現場の複雑さを減らすというより、整理する枠組みである
つまりestimandは、「何でも答える理論」ではなく、答えられないものを“答えられない”と明示する理論です。
正しさが増えるほど、運用が死ぬ
問題は、ここまでを“正しく”やろうとすると、現場の負担が一気に跳ね上がることです。研究離れが進む状況で、「議論が破綻しない」ための枠組みが、逆に「研究が進まない」原因になってしまう──この逆説は起こり得ます。
そこで必要なのは、「理論をさらに深掘ること」ではなく、運用を破綻させないための工夫です。
現場に優しい落としどころとしては、まずは次の割り切りが効きます。
「正しい理解」を目指すより、運用として
- まず“3択だけ決める”(現実込み/仮想世界/忍容性込み)
- Primaryは1つ、Secondaryは少数(2〜3)
- それ以上は感度分析の領域として、答えを1本に固定しない
これだけで、“深掘り無限ループ”から抜けやすくなります。
estimandの限界を、DSAはどう補うのか
ここからが本題です。DSAができる補填は、estimandの穴を埋めて万能にすることではありません。そうではなく、estimandが要求する前提(特にICE/欠測/異質性)で破綻しやすい部分を、データ側から“構造化”して運用可能にすることです。
1) ICE(中断・救済治療・併用薬)で議論が終わらない問題
ICEの扱いを決めるほど現実が複雑になり、議論が終わらない。ここに対してDSAは、ICEを「例外」ではなく観測されたイベントとして分布構造に保持し、誰が・いつ・どんな条件でICEを起こすかを構造で提示します。
要するに、ICEを「仕様書の文章」から「構造の図・パターン」に落とし、会話を前に進める役割です。
2) 欠測(無回答・途中離脱)で仮定が積み上がる問題
欠測補完は仮定が増え、“リアルワールド”から離れやすい。DSAはまず欠測を埋めずに、欠測そのもの(無回答/離脱)を解析対象化し、欠測がランダムでない構造(どの層で欠測が増えるか)を可視化します。
補完が必要なら、その後に「仮定が効く場所」を明確化して感度分析の設計に繋げる。いきなり仮定に突っ込まない、という順番が重要です。
3) 異質性(効く人・効かない人、AEが出る人)が平均値に潰される問題
平均効果は仕様として綺麗でも、現場が欲しい“層の違い”は見えない。DSAは平均ではなく分布構造で効果の多様性を示し、AE中断層/非中断層など現実に意味のある層を「除外せず」に扱い、「どの層で勝ち、どの層で負けるか」を説明可能にします。
4) DAG固定の主観(暗黙知)問題
DAGを固定しても主観は残る。DSAはDAGを自動生成して正解を保証するものではありませんが、DAGの取り方で結論が変わるときに、データ構造側から「このDAGだと無理筋では?」を示す材料になります。主観をゼロにするのではなく、主観のリスクを監査可能にする、という位置づけです。
5) “本当の想定外”が起きる問題
リアルワールドでは本当の想定外が起きます。DSAはそれを予言しません。ただし、分布構造の変化点を捉えやすく、「いつから別世界か」「どの層が変わったか」を切り分けて、主張の適用範囲を守ることに貢献します。
DSAは「難しいことを増やさず、破綻しにくい運用に寄せる」
estimandは、議論が破綻しないように条件が増える枠組みです。だからこそ、現場では運用が苦しくなります。
DSAは、estimandの限界(情報がない・現実が複雑)を消すのではなく、ICE/欠測/異質性/変化を構造として扱うことで、仮定の積み上げや恣意的除外に頼らず、現場で破綻しない運用へ落とすための補助線になります。
「完璧な理論」を追いかけて深く潜るよりも、現場が前に進むために、難しいことを“増やさないまま”正当性を守る。DSAが提供できる価値は、そこにあると感じています。

臨床研究の出発点は、日常診療で生まれるクリニカルクエスチョン(CQ)です。しかし、CQから仮説を立てて研究計画に落とし込む段階で、多くの若手医師がつまずきます。理由は単純で、そのCQは既知か、あるいは自身の経験不足による未知なのか、また仮説が「新しいかどうか」以前に、「因果として正しく問えているか」が分からないからです。
臨床研究の現場では、近年 estimand(推定したい因果効果の明確化) の重要性が広く共有されるようになりました。
「誰に」「何を」「何と比べ」「どのアウトカムを」「どの時間軸で」評価するのか。これを曖昧にしたままでは、研究計画も解析も議論にならない。ここまでは、すでに共通認識になりつつあります。
しかし、estimandを明確にしただけで、研究の再現性や妥当性が担保されるわけではありません。研究者の暗黙知や経験値による主観を客観にかえるためには、DAG(有向非巡回グラフ)の設計が重要です。
DAGは、因果仮説の設計図として、交絡、媒介、選択といった構造を明示し、「何を調整すべきか/してはいけないか」を決めるための中核的なツールです。estimandを現実の観察データに落とし込むには、DAGを避けて通ることはできません。
ところが現場では、こんな状況が繰り返し起きています。
- DAGは重要だと分かっているが、描ける人が限られる
- 描いても、研究者ごとに形が違う
- 指導医・統計家・臨床医の間で、合意形成に時間がかかる
- なぜそのDAGなのか、根拠を説明しきれない
- 結果が変わったときに、どこが弱かったのか振り返れない
つまり、DAGは因果推論の要である一方で、依然として研究者の経験や暗黙知に強く依存する“属人的な工程”になりがちなのです。
この属人性は、研究の質そのものを揺らします。
同じデータ、同じestimandであっても、DAGの描き方が違えば結論が変わることがある。しかも、その違いが「技術的な誤り」ではなく、「判断の違い」として処理されてしまう。これでは再現性も、説明可能性も、組織としての学習も積み上がりません。
ここで重要なのは、DAGを否定することではありません。
むしろ逆です。DAGが重要だからこそ、その設計品質をどう担保するかが、次の論点になります。
解析手法やAIモデルの高度化が進む一方で、因果設計の部分は「経験者が何とかする領域」のまま残っている。求められているのは、DAGという“仮説の設計図”を、再現性と説明責任に耐える形で扱うための品質管理の考え方です。
こうした問いに答えられる状態を作らなければ、estimandをどれだけ厳密に定義しても、研究の信頼性は頭打ちになります。 この壁をどう越えるか。その答えがDSA(分布構造分析)です(特許出願中)。