地震の発生「10年以内○%」と聞くと、当たるも八卦当たらぬも八卦のような気分になります。
その日の天気予報ですら予測が外れるのに、まして地下で起きる破壊現象を「いつ起きるか」まで当てるのは、現代科学ではまだまだ難しいのではないでしょうか。
それでも情報は、地震について「10年以内○%」のような確率論です。知りたいのは今日は傘を持っていけと言ってるの?です。問題は、結果的にその数字が当たる/外れるではありません。意思決定のプロセスになっているかです。
その数字が、何に依存していて、どこまでが観測で、どこからが仮定なのか。
ここが見えないまま確率が“答え”として独り歩きすることが、本質的な違和感の元です。
地震確率は「予測値」ではありません。
仮定・観測不足・モデル選択が圧縮された“合成物”です。
必要なのは予言ではなく、監査(audit)です。
既存の確率提示が抱える「科学的な穴」
地震の長期評価には、だいたい次の仮定が混ざっています。
- 定常性:発生率は一定とみなします(ポアソン的)
- 周期性:再来間隔があるとみなします(更新過程/BPT的)
- 独立性:他断層イベントの影響を薄く扱います
- 可観測性の幻想:地下応力のような主要因は観測できないため、代理指標で代替します
ここで最も危ないのは、これらが議論されるのではなく、確率1点に折り畳まれることです。1点になった瞬間に前提が消え、前提が消えた確率は社会の中で“権威の数字”になりやすいです。
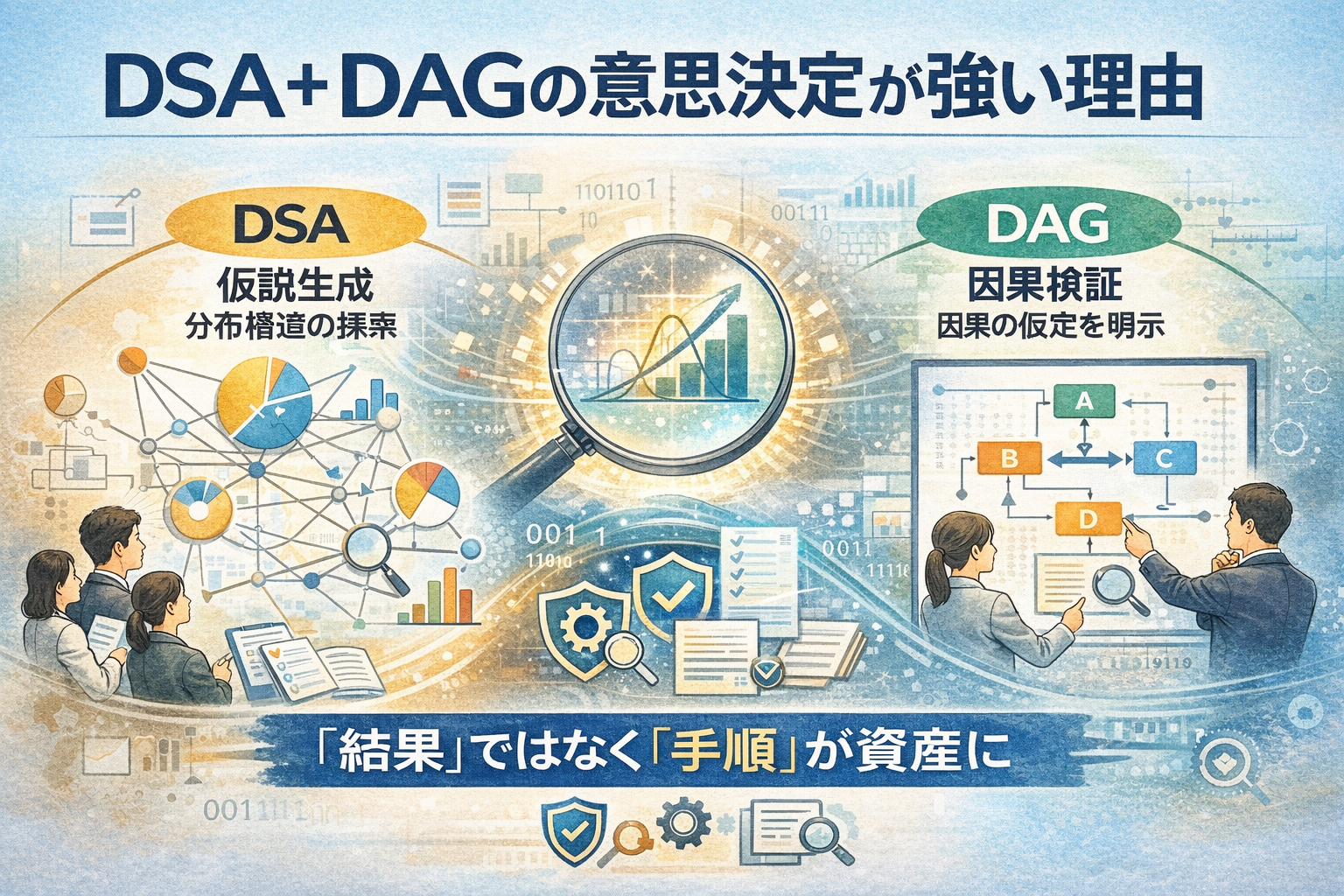
DSA+DAGがやることは「地震を当てる」ではありません
DSA+DAGでは、次のように定義されます。
- DSA:確率を点で出さず、確率そのものの分布を生成します(確率を確率変数として扱います)
- DAG:地震を因果で当てるのではなく、推定が歪む経路(不可観測→代理観測→モデル仮定→出力)を固定します
つまりDSA+DAGは、予測器ではなく、「確率生成プロセスの検査装置」です。
確率が“作られる”経路(推定が歪む経路のDAG)
以下は「地震を因果で当てるDAG」ではなく、確率推定がどこで歪むかを固定するDAGです。

この図のポイントは、R(T)が「自然から直接出てくる」わけではなく、
不可観測→代理観測→推定→モデル選択を経由して生成される、という構造を固定することです。
尖ったミニ・シミュレーション:確率監査(Probability Audit)
「30年以内70%」のような数字が出たとき、DSA+DAGではこう扱います。
Step 1:確率を作っている“部品”を分解します
- K:モデル選択(ポアソンか/更新過程BPTか)
- μ:平均再来間隔(推定誤差を含みます)
- α:周期の乱れ(周期性の強さの不確実性です)
- t0:最新イベント時期(推定幅があります)
- I:断層相互作用(周辺イベントの影響の強さです)
これらを 点ではなく分布として置きます。
Step 2:モデルを“混合”として扱います(ここが尖りです)
「どちらのモデルが正しいか」ではなく、モデル選択そのものを不確実性として扱います。
- K = Poisson(確率 1−w)
- K = BPT(確率 w)
- さらに w自体も固定せず分布として扱います(専門家の分布、合議の幅、など)
Step 3:10万回回して「確率の分布」を出します
各回で(K, μ, α, t0, I)をサンプルして P(10年), P(30年) を計算します。
すると出力は、単一の70%ではなく「確率分布」になります。
出力イメージ:P(30年)が二峰性+ロングテールになる例(概念図)
ここまで来ると、単一の「70%」は科学的にはこう見えます。

70%は結論ではありません。相反する仮説群を平均して丸めた“見かけの安定”である可能性があります。
不確実性の会計(Uncertainty Accounting)
監査の核心はここです。P(30年)の「揺れ」を、どの要因が支配したかを分解します。

この分解ができることで議論が変わります。
- K支配なら:追加の地質調査を増やしても確率は収束しにくい(モデル不確実性が残ります)
- μ/t0支配なら:追加観測・追加調査が「確率の品質」を上げ得ます
- 尾部(最悪側)を支配する要因が分かれば:防災は平均ではなく 尾を削る方向に設計できます
予測から「説明可能な意思決定」へ
地震に限らず、医療、政策、インフラ、金融など「当てにくいが決めねばならない領域」は、同じ構造を持っています。
点の確率は、説明責任を弱めます。分布と寄与分解は、説明責任を強めます。
DSA+DAGが提供するのは予言ではなく、“確率の説明責任”を実装する形式です。
私はこれを「予測」ではなく、Accountable Risk(説明可能なリスク)の設計だと捉えています。
議論のテーマは地震の当て方ではありません。
確率が社会で誤用される構造と、それを監査可能に戻す方法です。
(地震を例にしましたが、RWD→RWEでも同じです。)