ビジネスの現場では、グラフやダッシュボードが当たり前になりました。
売上推移、KPI達成率、顧客数、CV率、離脱率。数値は整い、見た目も分かりやすい。
しかし、そこで可視化されているのは、本当に「現実」そのものなのでしょうか。
私たちはしばしば、複雑なリアルワールドを、平均値や近似曲線、要約指標に押し込めて理解したつもりになります。
たしかに、その方が早いですし、説明もしやすくなります。
一方で、その瞬間に失われるものがあります。
それが、分布の内部にある構造です。
たとえば、平均が同じでも、中身はまったく異なることがあります。
一部に極端な高リスク群が潜んでいるのか。
中間層が厚いのか。
二極化が起きているのか。
ゼロがまとまって存在しているのか。
こうした違いは、平均や単純相関だけでは見えません。
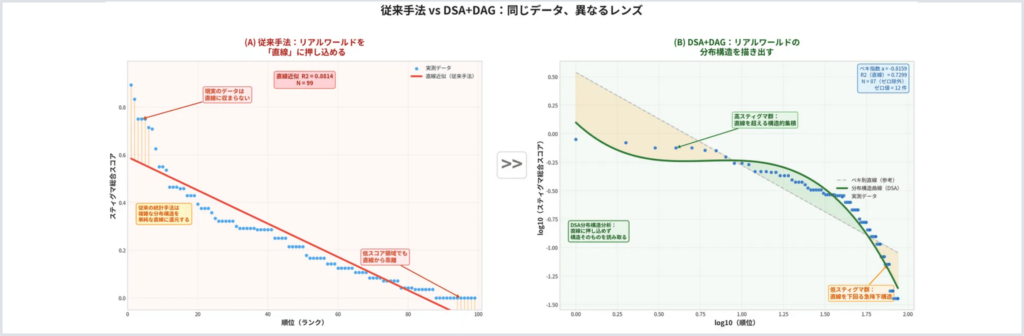
ここで重要になるのが、“値そのもの”ではなく、“値の並び方や偏り方”を見る視点です。
つまり、データを代表値に潰すのではなく、分布構造として読むという発想です。
私は、この発想が今後の意思決定において極めて重要になると考えています。
なぜなら、現実の課題は、きれいな正規分布でも、単純な直線関係でもないからです。
市場も顧客も患者も組織も、実際には歪み、偏り、裾の広がり、多峰性を持っています。
それにもかかわらず、従来の分析は、そうした複雑さを「ノイズ」として処理しがちでした。
しかし、本当に見るべきなのは、その“ノイズ”に見える部分かもしれません。
そこにこそ、異質性、閾値、分岐、そして因果のヒントが隠れている可能性があります。
DSA+DAGの考え方は、まさにそこに向き合うものです。
DSAは、実測値が理論分布からどのように乖離しているかを各点レベルで保持しながら、分布構造を可視化します。
そして、その構造を歪度、尖度、裾の広がり、多峰性、ゼロ集中などの観点から読み解きます。
さらに、その知見をもとに変数の役割を整理し、DAGへとつなげることで、平均や相関では見えにくかった因果構造の理解に近づきます。
これは単なる分析手法の違いではありません。
データをモデルに合わせるのか、データの構造から現実を読むのか。
その発想の転換です。
AI時代に入り、私たちは以前より多くのデータを扱えるようになりました。
しかし、データ量が増えるほど、単純化の誘惑も強くなります。
だからこそ今、必要なのは、より多く集めることだけではなく、どう読むかを変えることではないでしょうか。
見やすいグラフは、必ずしも現実をよく表しているとは限りません。
本当に重要なのは、整った線ではなく、その線からはみ出している現実の方かもしれません。