陰謀論は、なぜこれほどまでに強く、人の中に残り続けるのでしょうか。
それは単なる「誤情報」だからでは説明がつきません。むしろ重要なのは、「どのような構造でそれが成立しているか」です。
従来のアプローチでは、陰謀論は「正しいか、間違っているか」で評価されてきました。しかしこの視点では、なぜそれが広がり、なぜ信じられるのかという本質には到達できません。
ここで有効なのが、DSA(分布構造分析)とDAG(因果構造)の視点です。
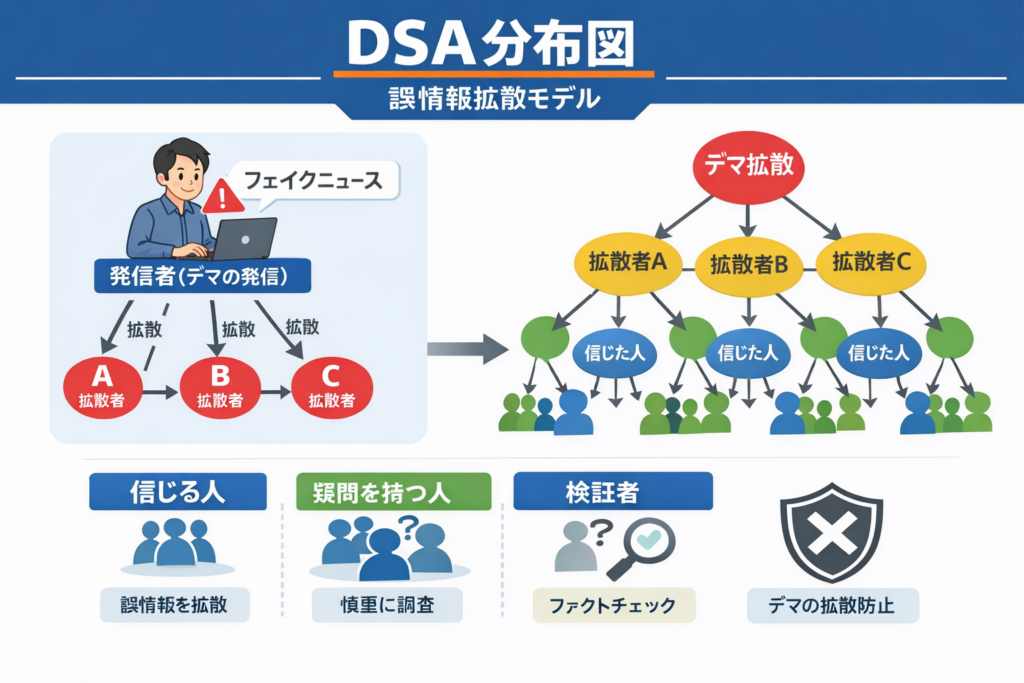
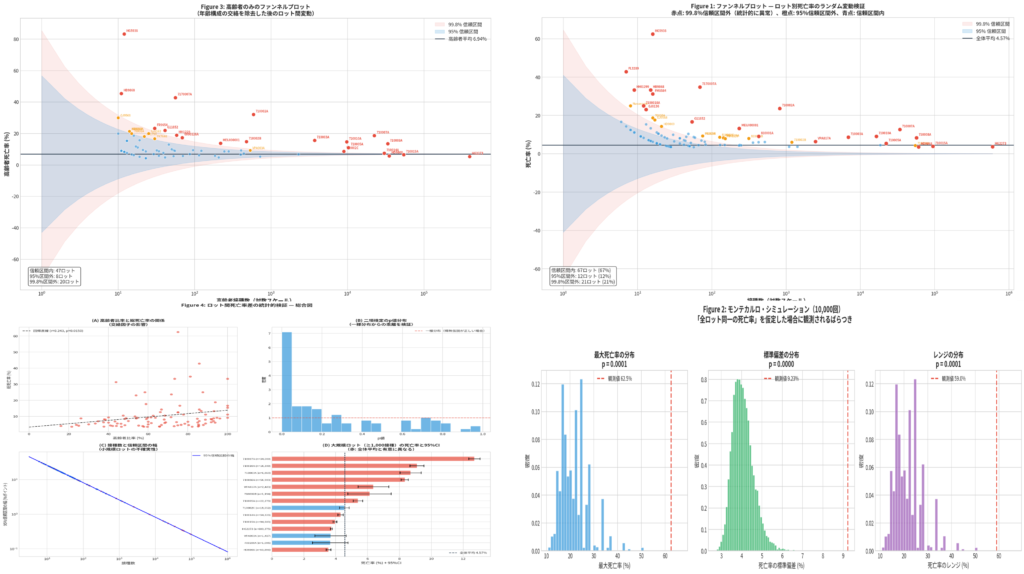
まずDSAで見ると、陰謀論は単一の主張ではなく、複数の要素が混在した「混合分布」として存在しています。
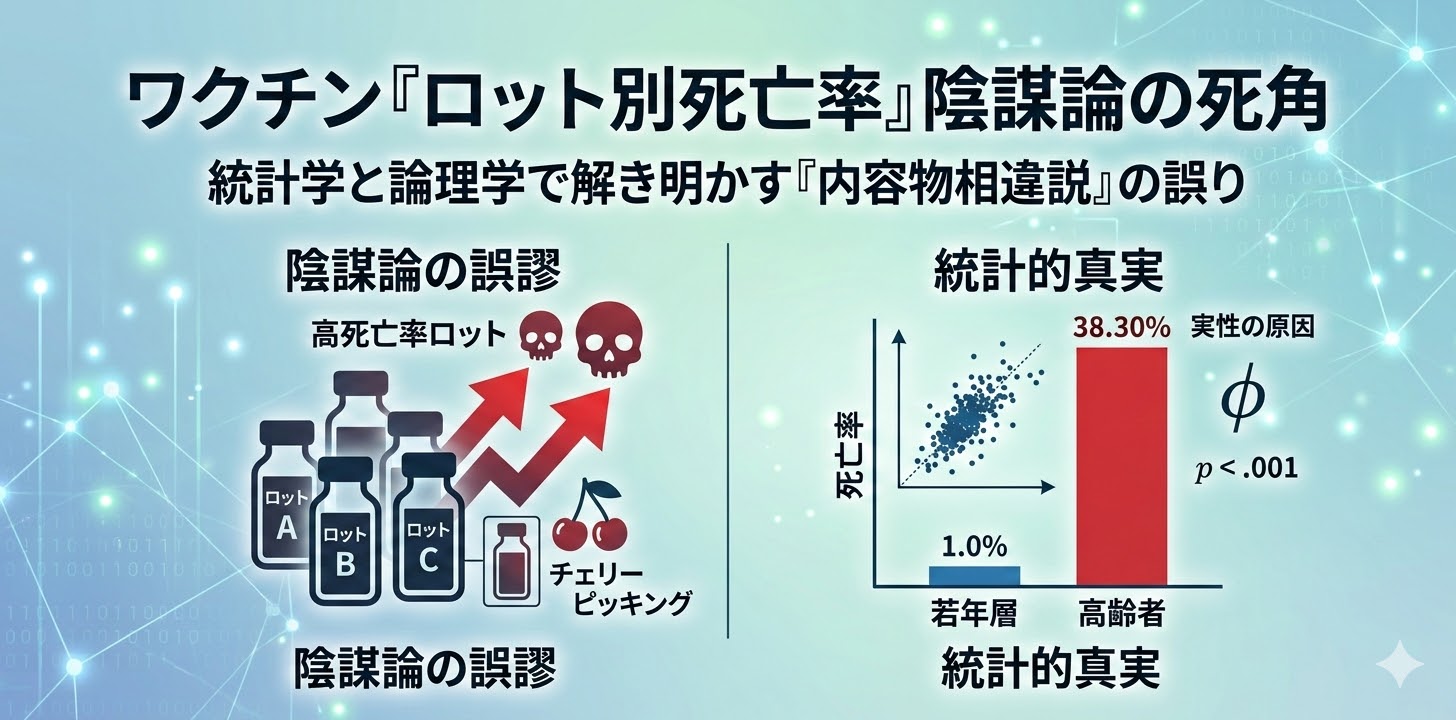
例えば、「一部の事実」「未確定情報」「誤情報」「強い感情」が同時に含まれています。この中でも特に重要なのが、“一部の事実”の存在です。これが分布の中で信頼の起点(フック)となり、全体の信憑性を底上げしてしまうのです。
つまり陰謀論は、完全な虚偽ではなく、「部分的に正しい構造」を持つからこそ強いのです。
次にDAGで因果関係を整理すると、さらに本質が見えてきます。
多くの場合、「不信(メディア・権威)」→「情報選択の偏り」→「誤情報の受容」→「確信の強化」→「拡散」という連鎖が成立しています。
ここで重要なのは、「誤情報そのもの」ではなく、「それを受け入れる構造」が存在している点です。
一度この因果ループに入ると、外部からの否定情報はむしろ“攻撃”として認識され、さらに信念が強化されるという逆説的な現象が起きます。
これはビジネスにも極めて示唆的です。
市場における意思決定もまた、「情報の正しさ」ではなく、「どの構造で受け取られるか」によって結果が変わります。どれほど正しいメッセージでも、受け手の分布構造や因果構造に適合しなければ、届かないどころか逆効果になることすらあります。
したがって重要なのは、「正しいことを伝える」ことではなく、「どの構造に介入するか」を設計することです。
分布を読み、因果を設計し、小さく介入し、再び構造の変化を観察する。この反復こそが、陰謀論のような強固な信念構造にも対応可能な唯一の方法です。
陰謀論は異常ではありません。
それは、人間の意思決定が「構造」に支配されていることを示す、極めてわかりやすい事例なのです。