冬季感染症の流行期、小児科外来ではインフルエンザ、COVID-19、RSVなどが重なり、発熱初日の乳幼児を前に「まず何をどう判断するか」が問われます。従来は、陽性か陰性か、どのウイルスかという“判別”が中心でした。しかし現場が本当に必要としているのは、確定診断そのものよりも、限られた初期情報から治療や再受診の優先度を見極める“予測”ではないでしょうか。
特に乳幼児では、鼻腔スワブ自体が大きな負担になります。泣く、暴れる、採れない、再採取になる。すると検査精度だけでなく、受診行動や治療開始タイミングにまで影響します。つまり課題は単なる検査法ではなく、「診断が成立するまでのプロセス」全体にあります。
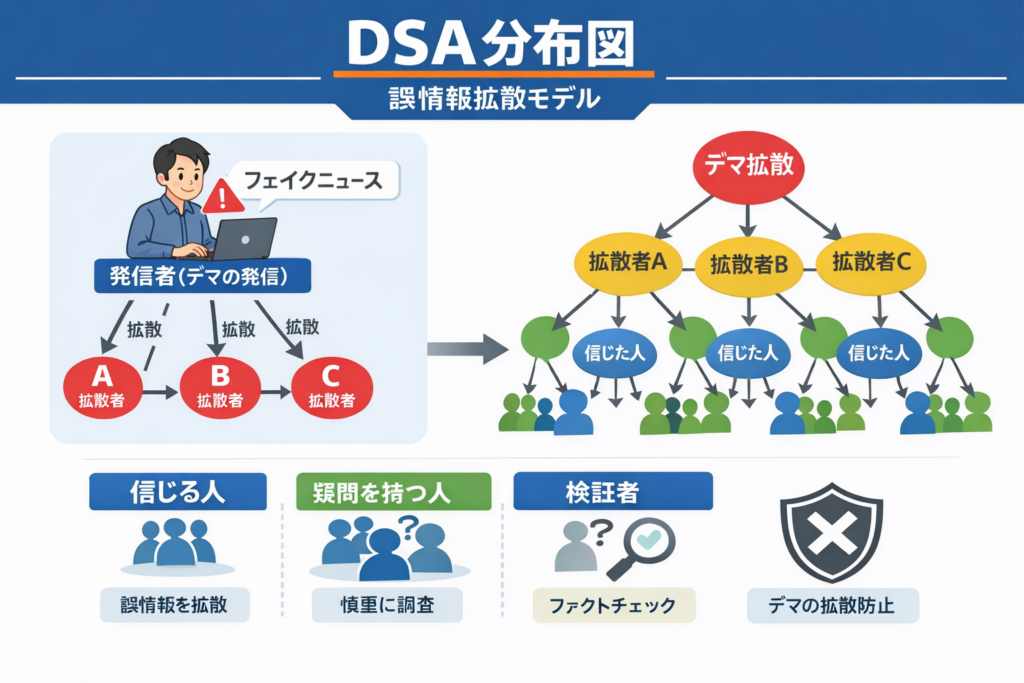
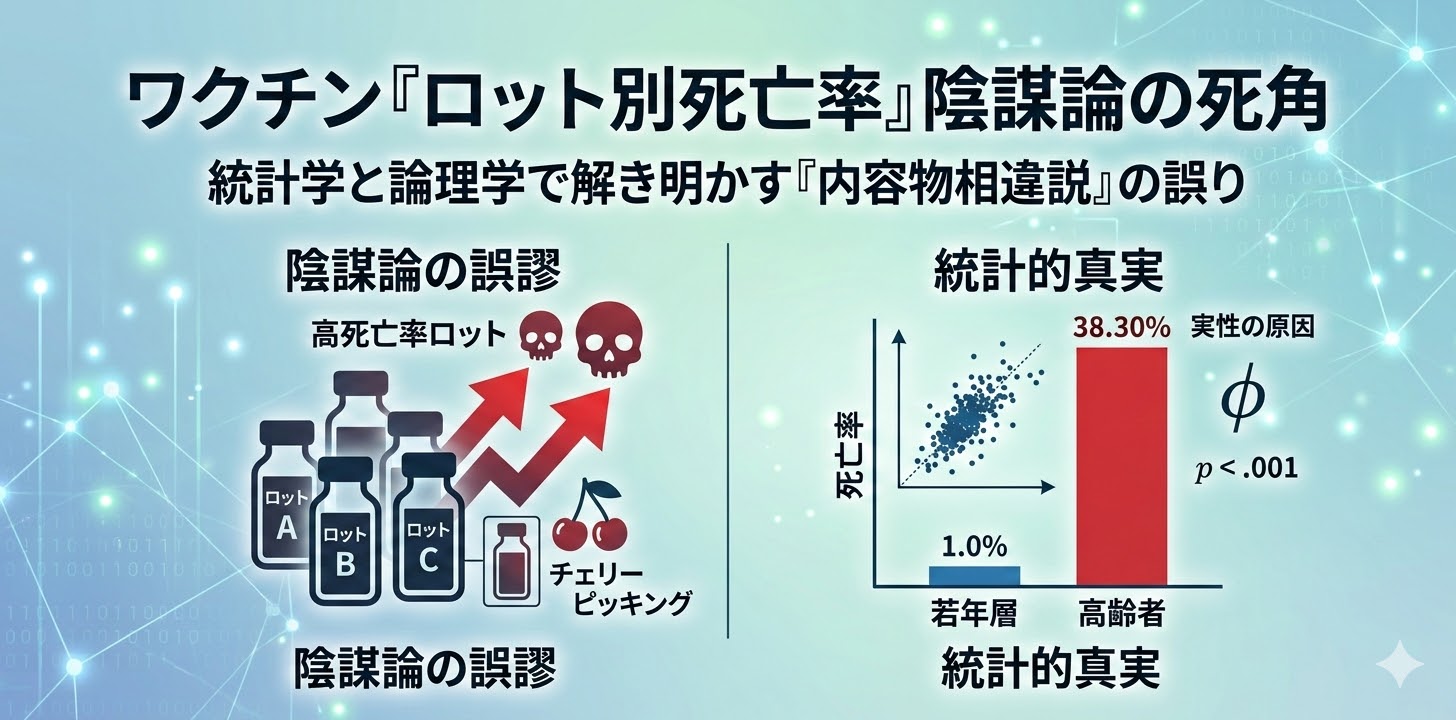
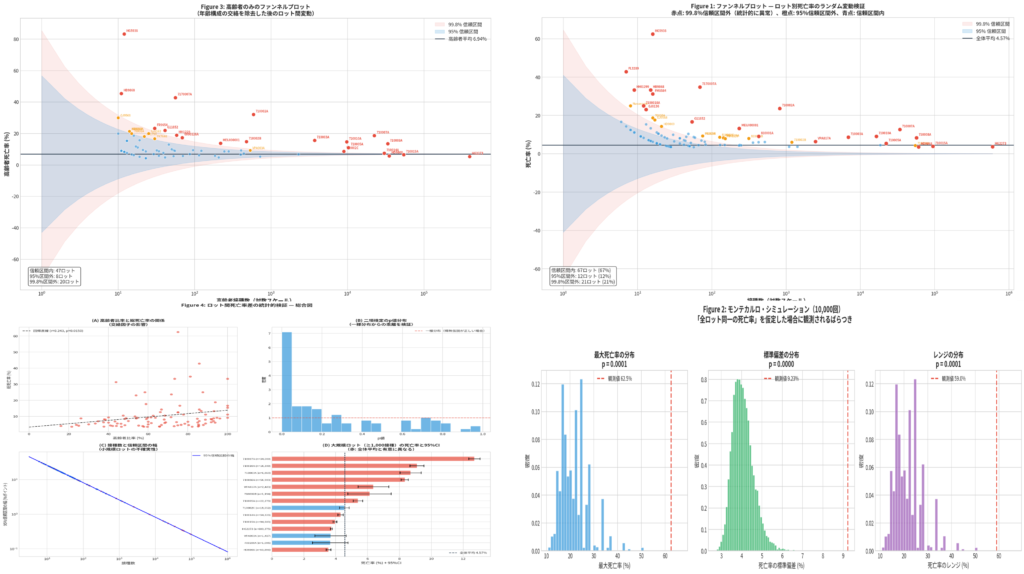
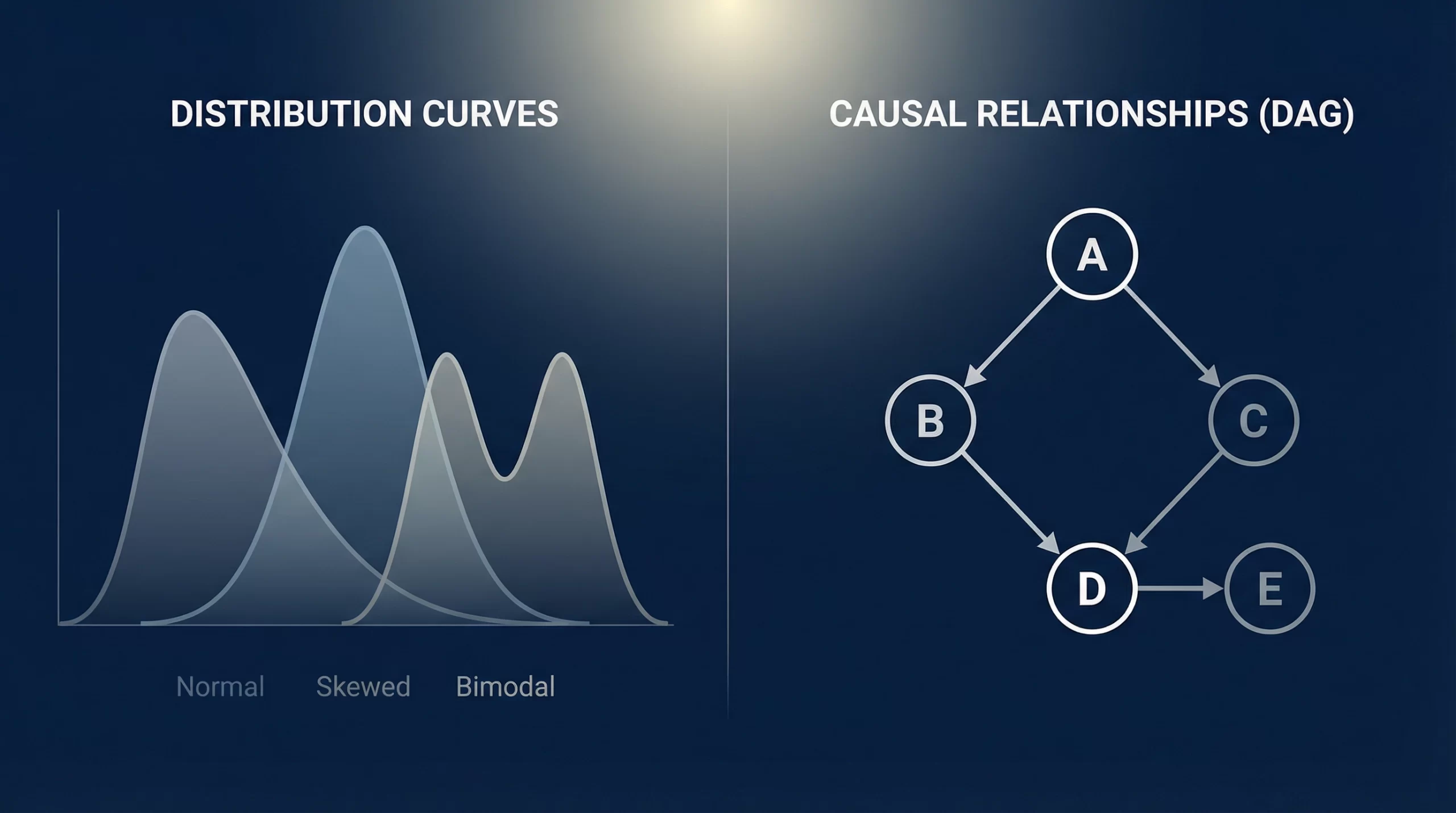
ここで重要になるのが、DSA+DAGの発想です。DSAは、発熱初日という同じラベルの中に潜む異質な分布構造を捉えます。例えば、高熱だが活気はある群、微熱でも呼吸器症状が強い群、家庭内曝露が濃厚な群など、平均値では潰れてしまう違いを見える化できます。さらにDAGを用いれば、月齢、症状、曝露歴、採取困難性、受診遅延、治療判断がどうつながるかを因果構造として整理できます。
これは「病原体を当てる技術」にとどまりません。むしろ、検査前の段階で誰を優先して診るべきか、誰に追加検査が必要か、誰に早期治療を考慮すべきかを支援する、“診断前意思決定技術”です。今後のフロンティアは、非侵襲検体の開発だけではありません。症状、行動、流行状況を含めた情報全体から、診療の再現性を高める構造を見出すことにあります。
判別だけに依存する時代から、予測と介入を設計する時代へ。乳幼児感染症診療は、その転換点にあります。異業種企業にも参入余地は大きいはずです。非侵襲採取デバイス、待合室トリアージ、保護者向け受診判断アプリ、外来支援アルゴリズムなど、価値創出のポイントは検査試薬の外側に広がっています。判別市場が成熟する中で、次に伸びるのは、予測と介入設計を担う周辺市場かもしれません。医療の現場課題を、単品開発ではなく構造で捉え直すことが、次の事業機会につながります。