

犯罪は全体的に満遍なく起きるのではなく、盲点を突いてきます。つまり外れ値や特異点です。相関の強さや確率の高さを中心とした従来型の統計手法が苦手な領域です。統計学は平均的な傾向を把握することに長けていますが、発生頻度が低く特殊な条件が重なった際に起きる犯罪の予測には得意ではありません。防犯において重要なのは、全体像に埋もれてしまう分布の偏りや特異点を特定し、その背後にある複雑な因果関係を解明することにあります。そこで、データの歪みや局所的な集積を捉えるDSAと、事象の構造を可視化するDAGを組み合わせる手法が有効となります。このアプローチにより、表面的な相関関係ではなく「なぜその場所で異常が起きるのか」という発生構造を深く理解することが可能になります。統計的な「典型」を追うのではなく、非典型的なリスクを科学的に捉える視点こそが、現代の防犯戦略には不可欠と言えるでしょう。

最近、データを入力すると因果構造を自動で可視化し、施策案まで提示してくれるサービス広告をSNSでよく目にするようになりました。
一見するとAIによる高度なサービスで非常に魅力的です。複雑な市場環境を整理し、売上向上のための意思決定を速めてくれるように見えるからです。
しかし、本当に重要な意思決定を任せるに足るのでしょうか。その意思決定に従ってリソースが投入されるのですから、アウトカムに確実につながる因果推論でなければなりません。
売上に直結する意思決定には責任が伴います。アルゴリズムの前提、変数の選び方、交絡の扱い、異質な集団の混在、欠損や外れ値への対応が曖昧なまま、それで「因果が見えました」と言われても、それは意思決定の根拠としては危うい。
見えているのは因果そのものではなく、あくまで“特定の前提の上で描かれた仮説”にすぎない可能性があるからです。
とくに注意すべきなのは、結果がきれいに見えるほど安心してしまうことです。
グラフが整っている、矢印がつながっている、AIが施策を提案してくれる。
その分だけ、「本当にその変数でよいのか」「平均の裏に異質な集団が隠れていないか」「結論が別条件で反転しないか」といった本質的な問いが置き去りになりやすいのです。
本来、重要なのは“見えること”ではなく、“どこまで信じてよいかが説明できること”です。意思決定支援ツールは、仮説を作る補助にはなります。
しかし、それだけで経営判断を委ねてよいわけではありません。
必要なのは、前提の点検、分布構造の確認、変数の役割整理、そして最終的な検証です。
この点で、私が重視しているDSA+DAGの発想は、単に因果の矢印を描くことではありません。
平均や相関だけでは見落とされる分布構造の歪み、異質性、二極化、群の混在を先に捉え、そのうえでDAGにより変数の役割や関係を整理する。
つまり、「何が効いていそうか」を急いで示す前に、「そもそもその比較や推論が成り立つのか」を確かめることに重心があります。
このアルゴリズムはAIの課題となるハルシネーションを抑えることにも有効です。
AI時代に必要なのは、見栄えの良い可視化に感動することではありません。
不確実性を不確実性のまま扱い、それでも意思決定できるだけの構造を持つことです。
“因果っぽく見えるもの”が増える時代だからこそ、経営には、以前にも増して方法論への目利きが求められているのではないでしょうか。
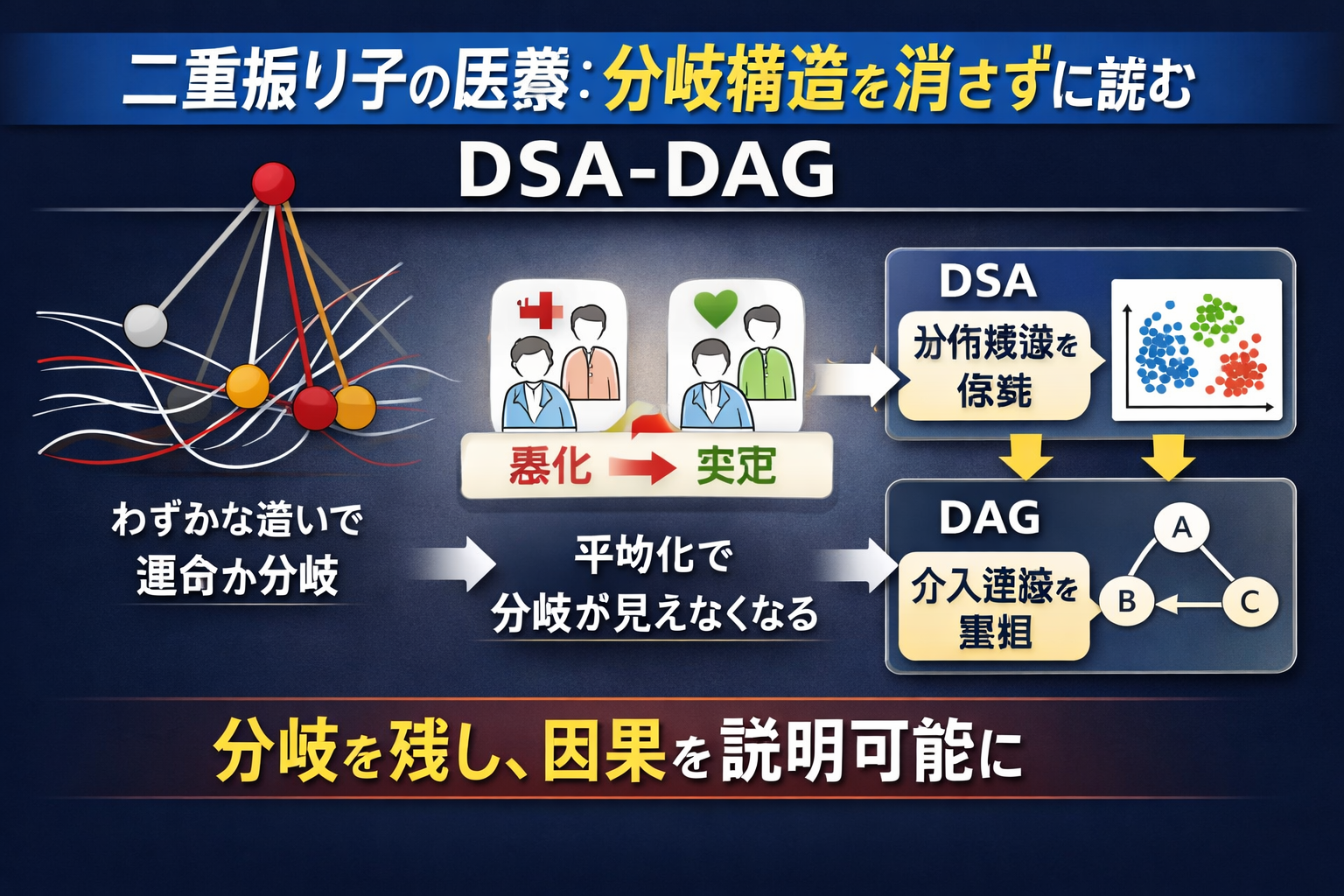
医療データは、初期条件に敏感に依存する傾向がしばしば見られます。これは、初期状態のわずかな違いが質的に異なる軌跡へと伝播していく二重振り子によく表れる現象です。臨床集団においても、患者の背景、併存疾患の負担、あるいは測定されていない生活習慣因子のわずかな違いが、結果に不釣り合いに大きな違いをもたらす場合、同様の分岐が生じます。因果分析の前にこれらの分布構造を平均化または平滑化する分析フレームワークは、治療反応の差異を生み出す分岐構造をまさに消し去ってしまう危険性があります。DSA-DAGは、この分岐構造を崩壊させるのではなく維持し、得られた構造マップを、品質ラベル付きの因果仮説生成を通じて説明可能な介入設計に結びつけるように設計されています。

二重振り子は、わずかな初期条件の違いが、時間の経過とともに大きな差となって現れる、典型的な非線形・カオス系として知られています。では、こうした現象は医療にも存在するのでしょうか。私は、概念としては十分に存在すると考えています。
もちろん、医療現場に物理学の二重振り子があるわけではありません。しかし実際の医療では、初診時にはよく似て見える患者が、その後まったく異なる経過をたどることが少なくありません。年齢、併存症、炎症状態、遺伝的背景、生活環境、治療開始のタイミング、医療者との関わり方――そうした小さな違いが、やがて重症化、回復、副作用、治療継続率といった大きな差につながります。
これは、平均値だけでは見えません。平均では「効果あり」「有意差あり」と整理できても、その内部では、よく効く群、効かない群、副作用が強く出る群が混在していることがあります。敗血症、がん、糖尿病、精神・心理領域、さらには行動変容を伴う慢性疾患管理などでは、こうした“分岐”が実務上きわめて重要です。
ここで必要なのは、平均的な患者像を前提に全体を捉える視点から、分布の中にどのような状態群が存在し、どこで経過が分かれるのかを見る視点への転換です。DSAはまさにそのために有効です。平均ではなく、分布の形、混在、偏り、裾、分岐の兆候を見る。そしてDAGは、その分岐に関与する要因が、どの経路を通じて転帰へつながるのかを構造化します。
医療における意思決定は、本来「平均的に正しい」だけでは不十分です。重要なのは、どの患者で、どの条件下で、どのように経過が分かれるのかを理解することです。二重振り子は、医療が本質的にそうした複雑系を含んでいることを示す比喩として、とても示唆的だと思います。
AI時代の医療分析に必要なのは、単に予測精度を競うことではなく、見えない分岐の構造を捉え、介入可能な因果へ翻訳することではないでしょうか。

天気予報の精度向上というと、多くの人は「もっと高性能なAIを使えばよい」と考えます。もちろん、それは重要です。しかし本質は、単に予測性能を上げることだけではありません。むしろ重要なのは、なぜ予測が外れるのか、その構造を理解することです。
この問題を考えるうえで興味深いのが「二重振り子」です。二重振り子は、見た目は単純な装置ですが、初期条件のわずかな違いで動きが大きく変わる典型的な非線形・カオス系です。天気もこれに似ています。物理法則に従っていても、初期値のごく小さな差が時間とともに増幅し、予測誤差として表れます。
ここで重要なのは、平均精度だけを見ても本質が分からないことです。平均的には高精度でも、特定の条件下では急激に外れることがあります。実務で問題になるのは、まさにこの「普段は当たるが、ある局面だけ大きく崩れる」という構造です。
DSA+DAGの価値は、ここにあります。DSAは平均ではなく、分布の形や混在する状態群を捉えます。つまり、「予測しやすい状態」と「急に予測困難になる状態」を分けて見る発想です。さらにDAGは、どの条件がどの中間過程を通じて誤差を拡大させるのかを整理し、改善すべき構造を見える化します。
これは天気予報だけの話ではありません。需要予測、在庫管理、株価変動、医療リスク予測など、現代のビジネスは不確実性の高い複雑系ばかりです。そこで必要なのは、「平均的に当たるモデル」よりも、「どの条件で崩れるのか」を理解できる視点ではないでしょうか。
AI時代の競争力とは、予測を当てる力そのものより、外れ方の構造を理解し、崩れやすい局面に先回りして介入できる力なのだと思います。二重振り子は、その本質を教えてくれる小さな模型です。

因果推論においてRCTは強力です。ApixabanとRivaroxabanの比較試験のように、「どちらの出血リスクが低いか」を平均的に示すには非常に有効です。しかし、現場の意思決定は本来それだけでは足りません。私たちが本当に知りたいのは、「なぜ差が出たのか」「誰にその差が成立するのか」「何を変えれば結果が変わるのか」という問いだからです。
従来の統計やRCTが主に示すのは、確率としての差です。つまり「平均的にはこちらが良い」という答えです。けれども医療もビジネスも、現実は平均では動きません。患者背景、併用薬、腎機能、行動、運用条件などが複雑に絡み合い、特定の条件でだけリスクが跳ね上がったり、逆に効果が強く出たりします。平均値だけでは、その構造は見えません。
ここで必要になるのがDSA+DAGです。DSAは、全体平均の裏に埋もれた分布の偏りや異質性を捉えます。どの層にリスクが集中しているのか、どこに見えない脆弱性があるのかを可視化します。DAGは、変数間の関係を単なる相関ではなく、因果仮説として整理します。つまり「結果が起きている確率」を見るのではなく、「結果を生んでいる構造」を捉えるための道具です。
重要なのは、これが分析の精緻化ではなく、意思決定の発想転換だということです。確率の高い選択肢を選ぶ時代から、因果構造を理解し、介入によって結果を変える時代へ。DSA+DAGは、そのための基盤になり得ます。これから必要なのは、有意差の有無ではなく、構造を読み、因果として判断する力です。

冬季感染症の流行期、小児科外来ではインフルエンザ、COVID-19、RSVなどが重なり、発熱初日の乳幼児を前に「まず何をどう判断するか」が問われます。従来は、陽性か陰性か、どのウイルスかという“判別”が中心でした。しかし現場が本当に必要としているのは、確定診断そのものよりも、限られた初期情報から治療や再受診の優先度を見極める“予測”ではないでしょうか。
特に乳幼児では、鼻腔スワブ自体が大きな負担になります。泣く、暴れる、採れない、再採取になる。すると検査精度だけでなく、受診行動や治療開始タイミングにまで影響します。つまり課題は単なる検査法ではなく、「診断が成立するまでのプロセス」全体にあります。
ここで重要になるのが、DSA+DAGの発想です。DSAは、発熱初日という同じラベルの中に潜む異質な分布構造を捉えます。例えば、高熱だが活気はある群、微熱でも呼吸器症状が強い群、家庭内曝露が濃厚な群など、平均値では潰れてしまう違いを見える化できます。さらにDAGを用いれば、月齢、症状、曝露歴、採取困難性、受診遅延、治療判断がどうつながるかを因果構造として整理できます。
これは「病原体を当てる技術」にとどまりません。むしろ、検査前の段階で誰を優先して診るべきか、誰に追加検査が必要か、誰に早期治療を考慮すべきかを支援する、“診断前意思決定技術”です。今後のフロンティアは、非侵襲検体の開発だけではありません。症状、行動、流行状況を含めた情報全体から、診療の再現性を高める構造を見出すことにあります。
判別だけに依存する時代から、予測と介入を設計する時代へ。乳幼児感染症診療は、その転換点にあります。異業種企業にも参入余地は大きいはずです。非侵襲採取デバイス、待合室トリアージ、保護者向け受診判断アプリ、外来支援アルゴリズムなど、価値創出のポイントは検査試薬の外側に広がっています。判別市場が成熟する中で、次に伸びるのは、予測と介入設計を担う周辺市場かもしれません。医療の現場課題を、単品開発ではなく構造で捉え直すことが、次の事業機会につながります。

陰謀論は、なぜこれほどまでに強く、人の中に残り続けるのでしょうか。
それは単なる「誤情報」だからでは説明がつきません。むしろ重要なのは、「どのような構造でそれが成立しているか」です。
従来のアプローチでは、陰謀論は「正しいか、間違っているか」で評価されてきました。しかしこの視点では、なぜそれが広がり、なぜ信じられるのかという本質には到達できません。
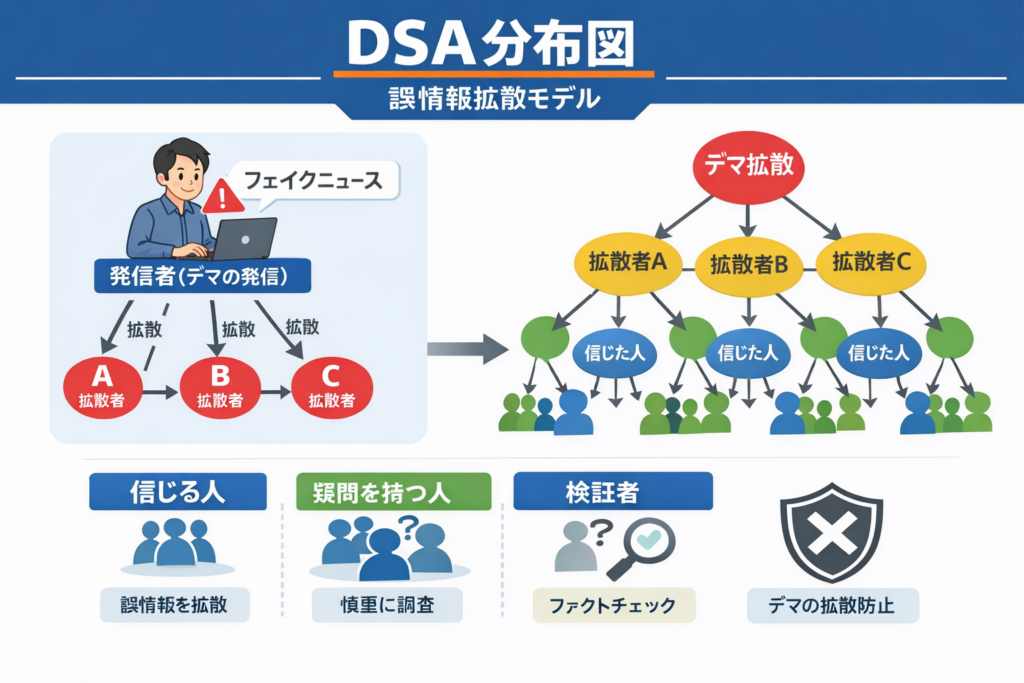
ここで有効なのが、DSA(分布構造分析)とDAG(因果構造)の視点です。
まずDSAで見ると、陰謀論は単一の主張ではなく、複数の要素が混在した「混合分布」として存在しています。
例えば、「一部の事実」「未確定情報」「誤情報」「強い感情」が同時に含まれています。この中でも特に重要なのが、“一部の事実”の存在です。これが分布の中で信頼の起点(フック)となり、全体の信憑性を底上げしてしまうのです。
つまり陰謀論は、完全な虚偽ではなく、「部分的に正しい構造」を持つからこそ強いのです。
次にDAGで因果関係を整理すると、さらに本質が見えてきます。
多くの場合、「不信(メディア・権威)」→「情報選択の偏り」→「誤情報の受容」→「確信の強化」→「拡散」という連鎖が成立しています。
ここで重要なのは、「誤情報そのもの」ではなく、「それを受け入れる構造」が存在している点です。
一度この因果ループに入ると、外部からの否定情報はむしろ“攻撃”として認識され、さらに信念が強化されるという逆説的な現象が起きます。
これはビジネスにも極めて示唆的です。
市場における意思決定もまた、「情報の正しさ」ではなく、「どの構造で受け取られるか」によって結果が変わります。どれほど正しいメッセージでも、受け手の分布構造や因果構造に適合しなければ、届かないどころか逆効果になることすらあります。
したがって重要なのは、「正しいことを伝える」ことではなく、「どの構造に介入するか」を設計することです。
分布を読み、因果を設計し、小さく介入し、再び構造の変化を観察する。この反復こそが、陰謀論のような強固な信念構造にも対応可能な唯一の方法です。
陰謀論は異常ではありません。
それは、人間の意思決定が「構造」に支配されていることを示す、極めてわかりやすい事例なのです。

AI時代に入り、アプリ制作、文章作成、画像生成、分析補助まで、個人でもかなりのことが実現できるようになりました。その一方で、いま急増しているのが、いわゆる「Thin wrapper」ビジネスです。これは、既存の大規模言語モデルや生成AIの上に、簡単なUIや使い方の導線を載せただけのサービスを指します。見た目は新しく見えても、実態は「基盤モデルを包み直しただけ」というケースが少なくありません。
この種のビジネスが増えている理由は明快です。基盤モデルそのものを開発するのは難しくても、その上に画面を作り、用途別に見せ方を整え、月額課金にすることは比較的容易だからです。しかも利用者の多くは、AIを直接使いこなすよりも、「最初から整えられた形」を求めます。そのため、AI時代の市場では、本質的な技術革新よりも、ラッピングの上手さで売るサービスが一気に増殖しています。
しかし、ここに大きな問題があります。Thin wrapperは参入障壁が低く、模倣が極めて容易です。今日売れた機能は、明日には他社が同じように実装できます。さらに、基盤モデル側の性能向上によって、昨日まで有料だった価値が、明日には標準機能として吸収されることも珍しくありません。つまり、「AIを使わせます」というだけのサービスは、AIそのものの進化によって価値を失いやすいのです。これでは価格競争から逃れられず、持続的な競争優位、すなわちMOATにはなりません。
では、何が生き残るのでしょうか。答えは明確です。これから必要なのは、AIを使うだけのサービスではなく、AIに何をさせるかを定義し、どの順番で、どの基準で、どこまで実行させるかを設計するサービスです。AIは非常に優秀な実行者ですが、自ら正しい問いを立てることはできません。問いが曖昧なら答えも曖昧になりますし、問いが誤っていれば、もっともらしく間違えます。だからこそ価値になるのは、AIの外側にある設計思想です。
今後のMOATは、UIの見やすさや会話のしやすさだけでは築けません。必要なのは、業界固有の業務知識、再現性ある判断基準、独自データ、業務プロセスへの深い組み込み、そして何よりAIに指示を与える側のロジックです。単にAIと対話できることは、もはや差別化ではありません。むしろ、Thin wrapperがあふれる時代だからこそ問われるのは、そのサービスがAIを使っているだけなのか、それともAIを従わせているのかです。
AI時代の競争は、AIを導入したかどうかでは決まりません。勝敗を分けるのは、AIに仕事をさせるための構造を持っているかどうかです。Thin wrapperが増えれば増えるほど、この差はより鮮明になります。生き残るのは、AIの上に薄く乗るサービスではなく、AIの行動そのものを規定するサービスです。そこにしか、本当のMOATは生まれません。

DSA(分布構造分析)とDAG(有向非巡回グラフ)を組み合わせることで、因果推論における客観性を高める手法について解説しています。従来のDAGは専門家の主観に依存しやすいという弱点がありましたが、本手法はDSAによってデータの歪みや層を事前に把握し、仮説の精度を向上させることを目指します。最も重要な点は、単なる静的なデータ分析にとどまらず、介入後に生じる構造変化を観測することで因果仮説の妥当性を検証するという動的なアプローチにあります。これにより、主観的な仮説を反証可能で監査可能な科学的プロセスへと引き上げることが可能になります。既存の構造探索AIとは異なり、因果を変化のプロセスとして捉える点に、この手法独自の新規性と優位性が存在します。