新型コロナウイルスワクチンに関する陰謀論の一つに、「ロットごとに内容物が異なり、特定のロットで死亡率が高い(意図的に毒性が変えられている)」という主張があります。この説は根強く、現在も沈静化の兆しが見えません。
今回、「mRNAワクチン中止を求める国民連合」等の団体が公開している「ロット別死亡率TOP100」のデータを基に、統計的な分析を行いました。
統計的実在と因果関係の乖離
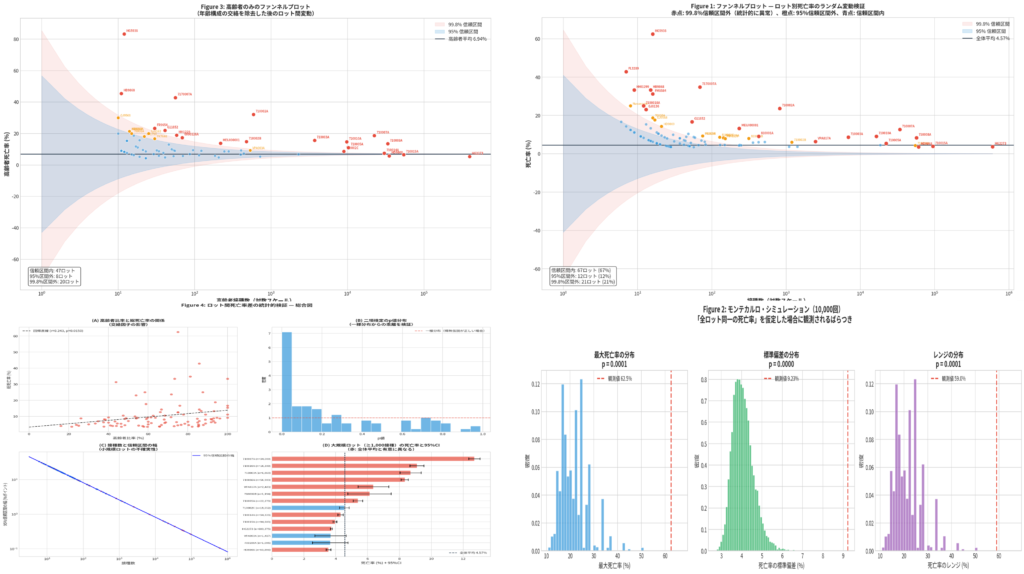
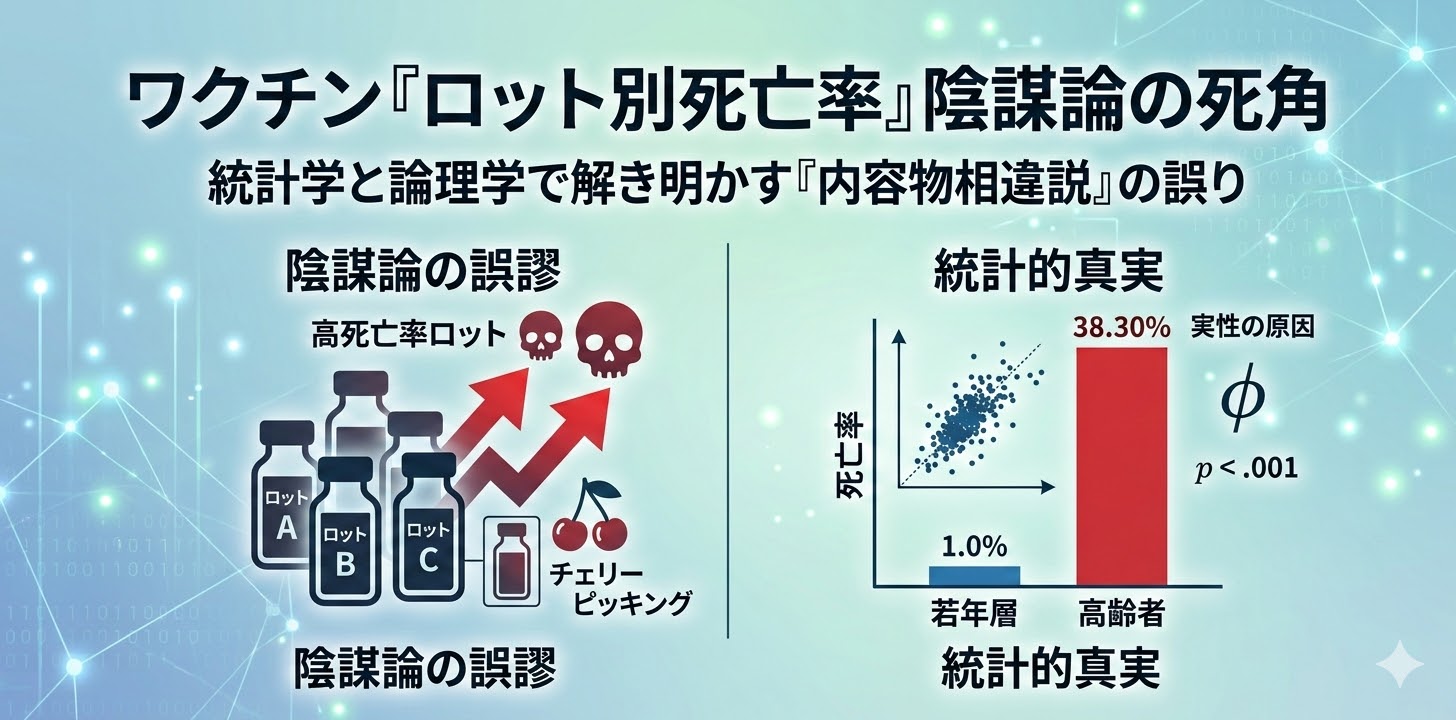
結論から述べれば、本データにおいてロット間の死亡率に差があることは統計的事実です。「全ロットの死亡率は同一である」という帰無仮説は明確に棄却されます(過分散パラメータ $\phi = 244.5, p < .001$)。
しかし、「死亡率に差があること」と「意図的に内容物が変更されていること」は論理的に全く別の命題です。分析の結果、後者の「内容物が異なる」という結論を導くことはできませんでした。観測された変動は、以下の既知の要因によって十分に説明可能です。
変動を説明する3つの要因
- 「少数の法則」による統計的ノイズ
死亡率が最も高いとされるロット(例:HG群 62.5%)は、分母となる接種数がわずか16人です。このように極端な数値は、接種数が極端に少ない場合に生じる統計的な振れ幅(ノイズ)に過ぎません。陰謀論で引用される「高死亡率ロット」の多くは、接種数が100未満の極小ロットです。
- 接種対象者の属性(年齢構成)の違い
高齢者の死亡率(約6.9%)は若年層(約0.06%)の約116倍に達します。高齢者施設などに優先配布されたロットは、集団のベースラインとしての死亡率が必然的に高くなります。実際に、高齢者比率と死亡率の間には強い正の相関($r = 0.82, p < .001$)が確認されました。
- 未測定の交絡因子
本データには、基礎疾患の有無、接種時期、施設特性、死亡の定義(接種後何日以内か)など、死亡率に影響を与える重要変数が含まれていません。これらを調整(重回帰分析等)しない限り、「内容物の差」を結論づけることは科学的に不可能です。
論理的誤謬とチェリーピッキング
「特定ロットで死亡率が高いから、内容物が異なるはずだ」という推論は、論理学における**「後件肯定の誤謬」**に該当します。
「内容物が異なれば、死亡率に差が出る」という命題が真であっても、その逆である「死亡率に差があるから、内容物が異なる」は真とは限りません。
また、大規模ロットでの安定した数値を無視し、小規模ロットの極端な外れ値のみを抽出して主張する手法は、典型的な**「チェリーピッキング(証拠の選り好み)」**と言えます。
結論:真の原因特定に必要なデータ
現時点でロット間の死亡率差を科学的に検証するためには、以下のデータが不可欠です。
- 個人レベルの詳細: 年齢、性別、基礎疾患、接種回数、接種日、死亡日
- 施設・流通レベル: 接種施設の種類(病院・高齢者施設)、地域、製造・出荷日、保管条件
- 定義の統一: 死亡の定義の厳密な設定
これらの包括的なデータがない状況で、「内容物が異なる」と断じることは、科学的根拠を欠いた憶測の域を出ません。