


NHANES公開データを用いて、米国成人8,013名の収縮期血圧(SBP)をDSAで探索的に解析しました。
今回あらためて見えたのは、従来の平均値中心の見方では、集団の内部構造がかなり失われてしまうということです。
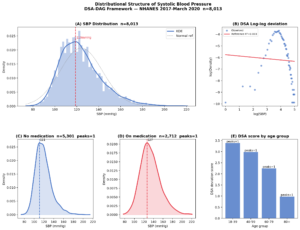
全体のSBP分布は119mmHg付近にピークを持ちながら、右裾に高血圧域が広がる非対称な構造を示しました。つまり、「平均的には大きな問題がない」と見えても、内部には高値側へ偏った群が確かに存在しているということです。
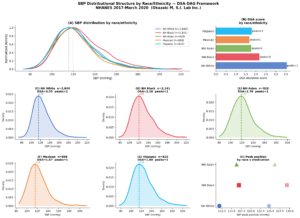
さらに、降圧薬の使用有無で分布を分けると、非使用群のピークは111mmHg、使用群は127mmHgとなり、16mmHgの構造的シフトが確認されました。これは単なる平均差ではありません。背景の異なる集団が、異なる分布構造を持っていることを示しています。
年齢層別では、若年層ほどDSA偏差スコアが高く、高齢層ほど低下する傾向が見られました。若い世代ほど生活習慣や未診断群を含む不均一性が大きく、高齢層では診断・治療を通じて分布が相対的に集約されている可能性があります。
重要なのは、DSAが「平均値」ではなく、「分布の歪み」「裾の重さ」「ピーク位置」「構造のズレ」を見る点です。
従来手法がリアルワールドを代表値に押し込めるのに対し、DSAはリアルワールドを構造として捉えます。
もちろん、今回の解析は探索的です。横断データであり、因果を確定するものではありません。サンプルウェイト未適用、降圧薬変数の欠測処理など、慎重に扱うべき限界もあります。
しかしそれでも、平均だけでは見落とされる集団内の異質性を可視化できた意義は小さくありません。
ビジネスでも医療でも同じです。
全体平均が安定しているからといって、現場の構造まで安定しているとは限りません。
本当に見るべきなのは「平均」ではなく、「中で何が起きているか」です。
DSAは、その“見えない構造”を捉えるための視点です。