日本の人材評価において、長らく「偏差値」は絶対的な物差しとして君臨してきました。進学から就職、果ては人生の豊かさの指標にまで、この「平均からの距離」を示すたった一つの数値が、強力なパワーを持ち続けています。
しかし、データサイエンスの視点から見れば、偏差値による評価は「情報の暴力的搾取」に他なりません。
平均と正規分布という「虚構」
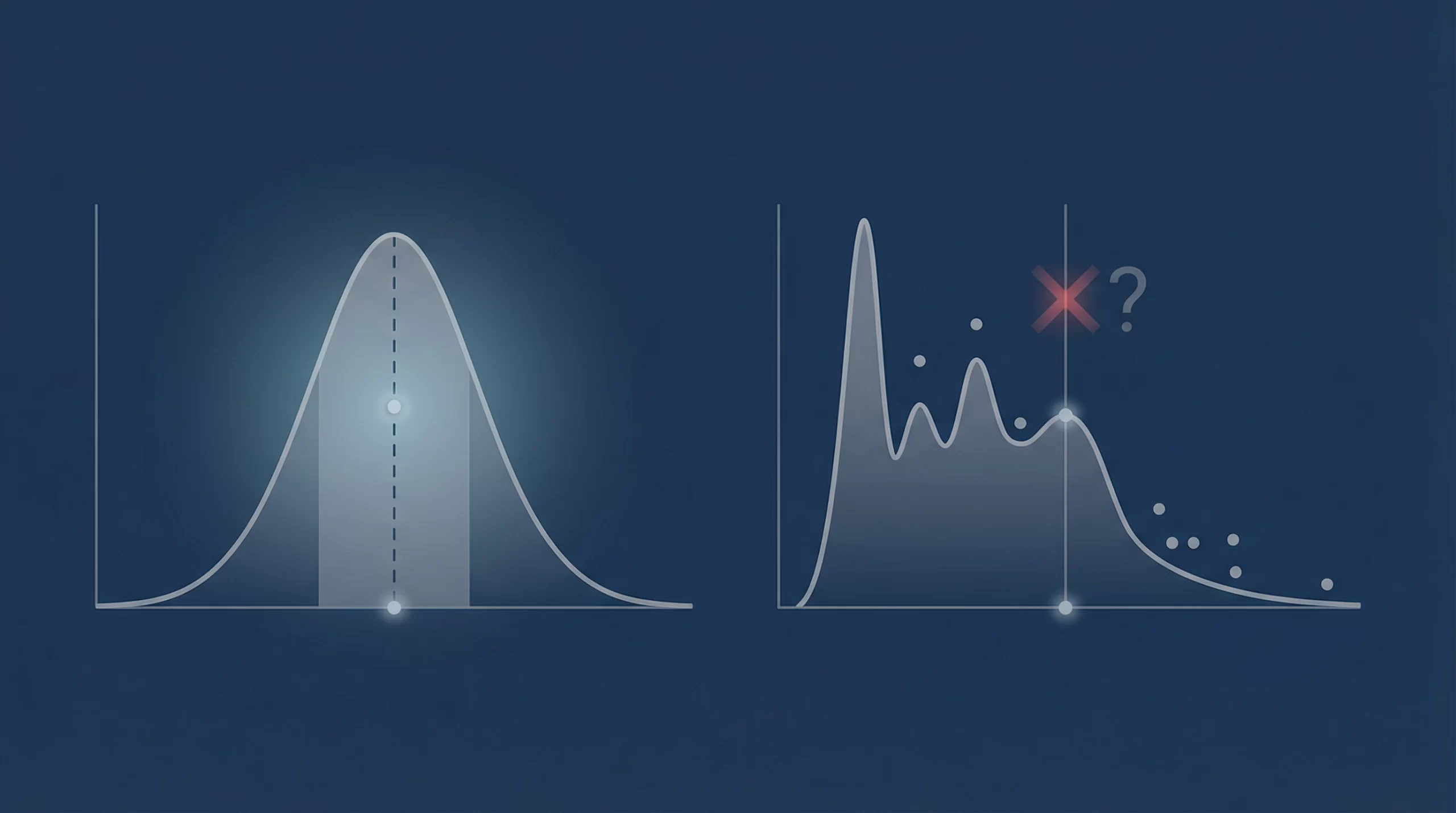
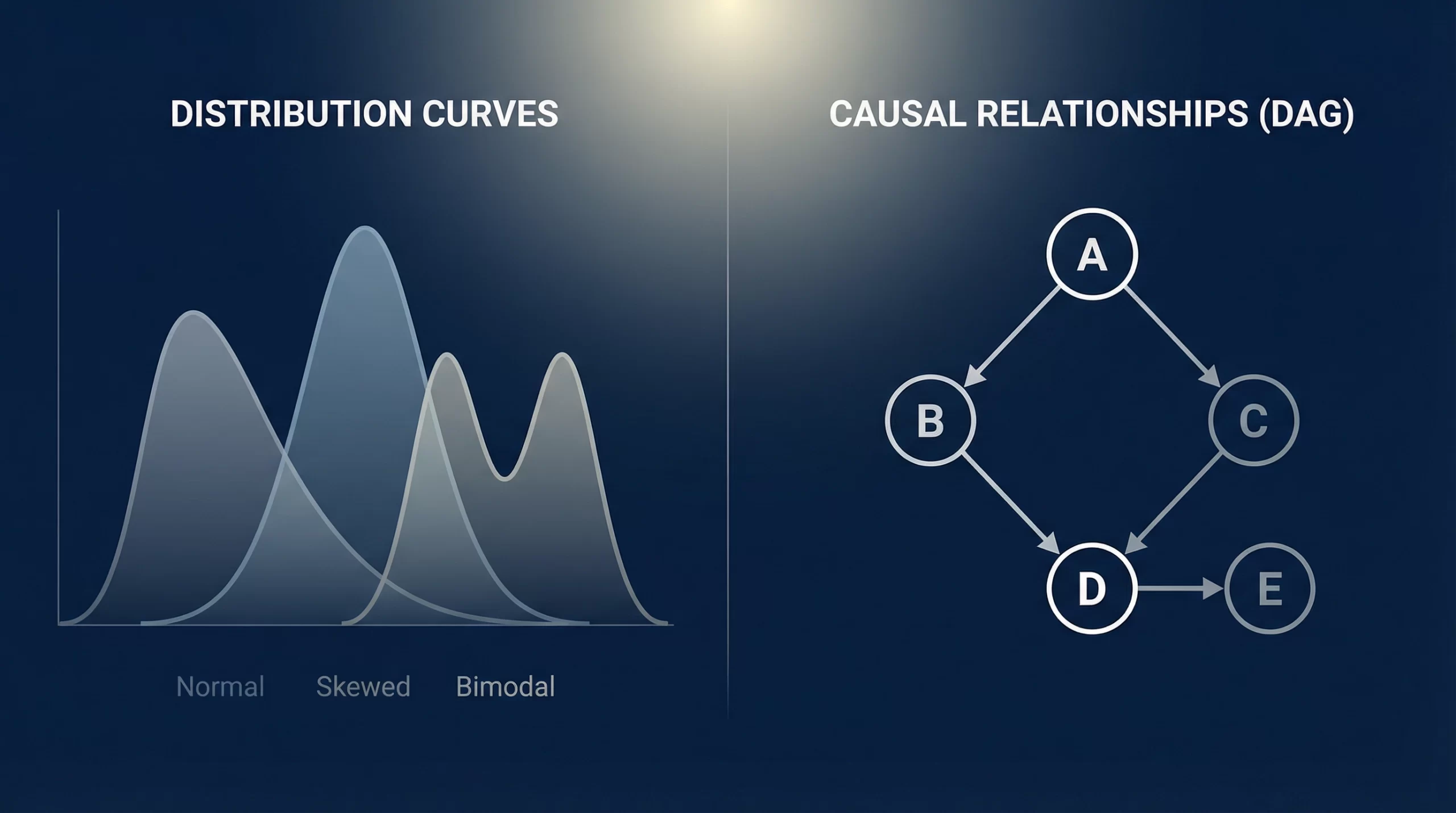
偏差値は、データが美しい鐘型の「正規分布」を描くことを前提としています。しかし、人間の才能や可能性は、果たしてそんなに単純でしょうか? 本来、一人の人間は、論理的思考、共感性、創造的衝動、あるいは「特定の環境下でのみ発揮される集中力」など、無数の変数が複雑に絡み合った「多次元の分布構造」を持っています。
偏差値というシステムは、この豊かな多次元データを強引に圧縮し、一本の一次元の軸に乗せてしまいます。このプロセスで、その人の個性を形作っていた「分布のうねり」や「特異な輝き」は、すべて「ノイズ」として切り捨てられてしまうのです。
構造(DAG)と分布(DSA)で見直す「沈黙」の価値
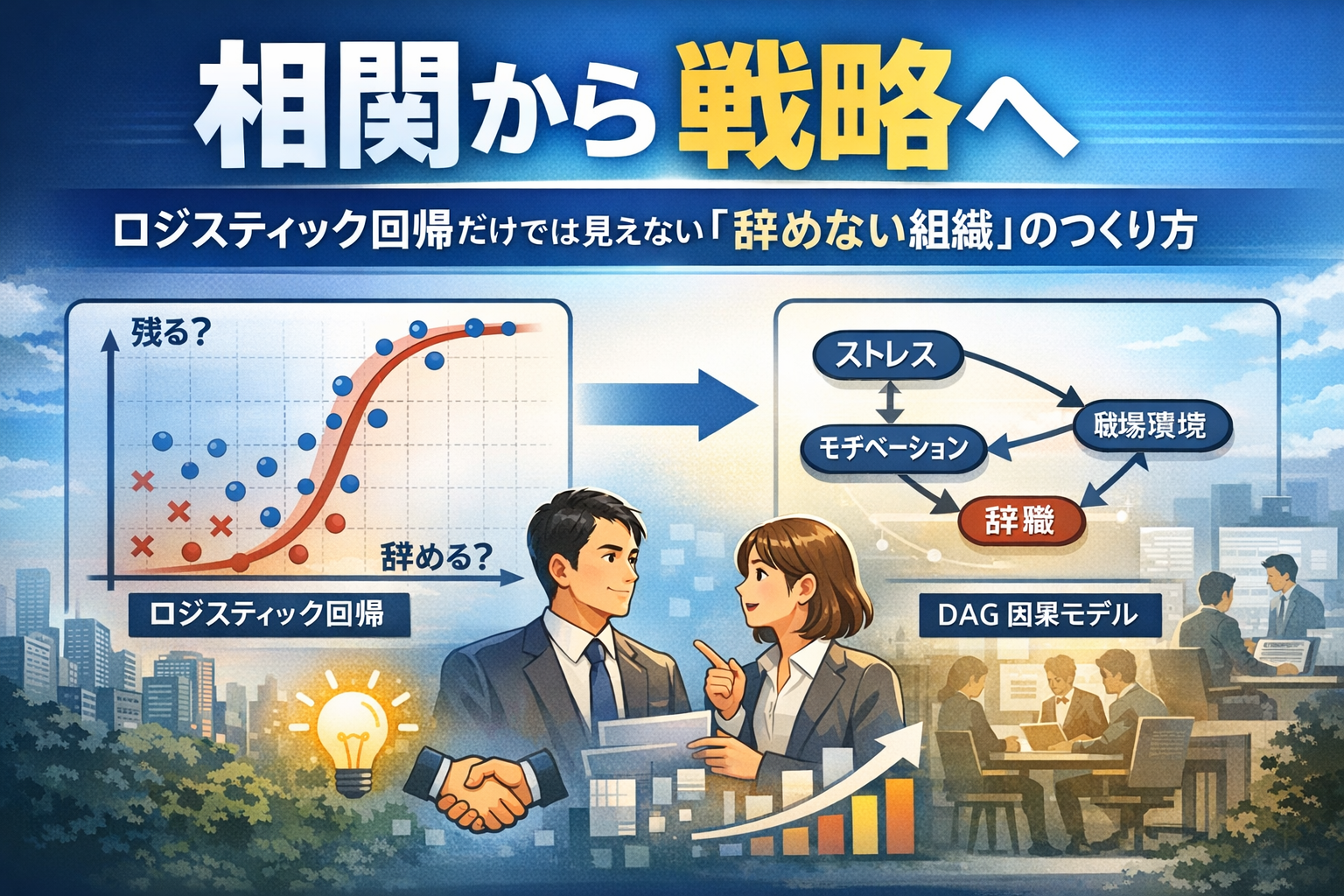
ここで、因果推論の新潮流であるDSA(分布構造分析)+DAG(有向非巡回グラフ)の視点を導入してみましょう。 例えば、テストで低い点数を取った、あるいは「無回答」だった生徒がいたとします。従来の偏差値教育では、それは単に「能力が低い」という一点に集約されます。
しかし、DAGでその背後にある因果構造を可視化すれば、そこには「完璧主義ゆえの防衛本能(スティグマ)」や「家庭環境による心理的圧迫」という矢印が見えてくるかもしれません。そしてDSAによって分布全体を眺めれば、彼が「平均」から外れているのは能力の欠如ではなく、特定の要因によって「分布が歪められているだけ」だという真実が浮かび上がります。
「答えない」「解けない」という行動の裏側にある構造を読み解くことこそが、真の評価ではないでしょうか。
「平均」を捨て、構造への愛
これからの世の中に求められるのは、人間を偏差値的な「一次元の順位」で並べることではありません。 一人ひとりが持つ複雑な因果の網目(DAG)を理解し、その才能が最も美しく発動する分布(DSA)の形を整えること。つまり、「モデルに人間を合わせるのではなく、人間の構造をモデル化する」姿勢です。
偏差値という「一次元の檻」を壊した先にこそ、多様性が真に機能する、解像度の高い社会が待っています。私たちは今、統計学の「平均」という幻想を捨て、人間という「構造」に向き合う歴史的転換点に立っているとおもいませんか?